DRS is a well known feature of vSphere which is designed to help load balance virtual environments for optimal performance.
With most virtual workloads, DRS does an excellent job of load balancing, so leaving DRS set to “Fully Automated” without specifying any DRS rules is fine.
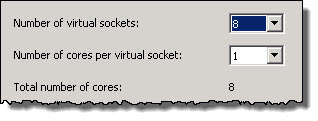
The “Migration Threshold” can be adjusted from Conservative to Aggressive in 5 increments, with the default being “3” which I recommend.
For more information on this recommendation see : Example Architectural Decision – DRS Automation Level
These two settings are shown below:

However with MS Exchange VMs which are CPU and RAM intensive, it doesn’t make sense to have these VMs moved around automatically if it can be avoided. If Exchange MBX / MSR VMs were vMotioned, it may take several minutes for the process to complete, during which time, depending on the vMotion configuration and bandwidth, could result in performance degradation. As a result, avoiding vMotion where possible reduces the risk to Exchange.
Note: I am not saying vMotion does not work, or cannot be configured to work very well for large VMs like MBX/MSR, but if vMotion can be avoided without adding significant complexity or operational cost to an environment, I try to avoid it except during planned maintenance activities.
I still however recommend enabling DRS and configuring it in “Fully Automated” mode, but by combining it with DRS rules for MBX / MSR VMs we can provide both higher and more consistent performance for MS Exchange.
To achieve this I recommend the following:
Create a “Host DRS Group” for each ESXi host in the cluster where Exchange VMs are expected to run and naming them with the ESXi hosts name to make them easily identifiable.

Next I recommend creating a “VM DRS Group” per Exchange Mailbox VM and naming the VM DRS Group as the Exchange MBX or MSR server name OR another easily identifiable name such as “Exchange DAG Node 1” shown below.

Now that we have our “Host DRS Group/s” and “VM DRS Group/s” created, we setup a DRS “Virtual Machines to Hosts” rule per MBX/MSR VM and ESXi host with the policy “Should run of hosts in group” as shown below.

What the above rule does is ensure the MSR or MBX VM runs only on the specified ESXi host unless there is an ESXi host failure, in which can it can automatically restart on another node within the cluster.

The below screenshot shows an example of what the recommended DRS rules would be in an environment had four MSR or MBX servers. 
The above rules will result in the MBX or MSR VMs running on separate hosts as shown below.

Advantages of this DRS configuration:
1. Ensures no compute or network contention between the Exchange VMs
2. Ensures no storage layer contention between Exchange VMs such as HBA queue depths, NIC Note: This will not eliminate storage contention which may exist at a SAN/NAS layer.
3. DRS will not automatically move an MBX or MSR VM meaning performance will not potentially be impacted by the vMotion activity
4. HA is still fully functional
5. vMotion can still be used if required. e.g.: Prior to host maintenance.
6. DRS will still automatically load balance VMs throughout the cluster to ensure optimal performance of all ESXi hosts
7. More efficient than simply using Anti-Affinity rules for MBX/MSR VMs
8. Ensures two or more DAG members will not be impacted in the event of a single ESXi host failure.
Recommendations for DRS:
1. Set DRS Automation level to “Fully Automated”
2. Setup DRS “Migration Threshold” to “3” (Default)
3. Setup a “VM DRS Group” per Exchange Mailbox VM
4. Setup a “Host DRS Group” on a 1:1 basis with Exchange MSR or MBX VMs
5. Setup a DRS “Virtual Machines to Hosts” rule with the policy “Should run of hosts in group” on a 1:1 basis with Exchange MSR or MBX VMs & ESXi hosts
6. Disable Distributed Power Management (DPM) for hosts running Exchange MBX/MSR VMs.
Back to the Index of How to successfully Virtualize MS Exchange.