A common question recently has been how should I size a solution with Erasure Coding (EC-X) from a capacity perspective.
As a general rule, any-time I size a solution using data reduction technology including Compression, De-duplication and Erasure Coding, I always size on the conservative side as the capacity savings these technologies provide can vary greatly from workload to workload and customer to customer.
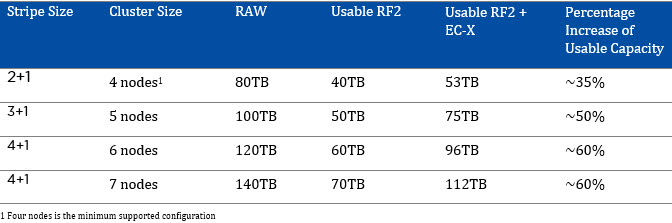
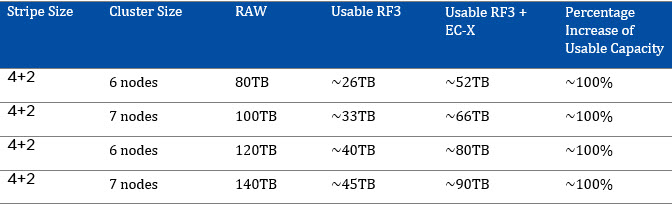
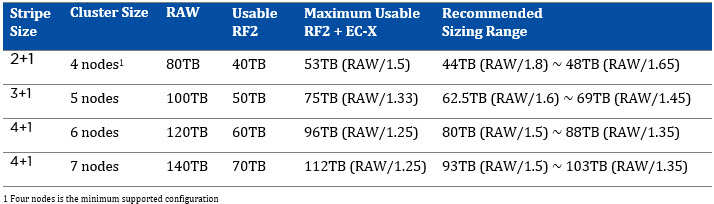
To assist with sizing, I have created the below tables showing the RAW capacity, usable capacity based on RF, Maximum usable with EC-X and my recommended sizing range.
You will note the recommended sizing is a range between roughly 50-80% of the theoretical maximum capacity EC-X can provide.
This is because EC-X is a post process and is only applied to Write Cold data as per my earlier post: What I/O will Nutanix Erasure coding (EC-X) take effect on?
This means it is unlikely all data will have EC-X applied and as a result, the usable capacity will generally be less than the maximum.
The following are general recommendations, which may not be applicable to every environment. For example, if your workload is heavy on “overwrites”, your EC-X capacity savings will likely be minimal, but for general server workloads, the below can be used as a rule of thumb:
RF2 + EC-X Recommended Sizing Range
RF3 + EC-X Recommended Sizing Range
If you want to be conservative with sizing, I recommend choosing the lower value in the sizing range. If you are happy to be less conservative then the higher number in the range can be used.
If you decide to size based on a number outside the recommended range, please document the assumed EC-X data reduction ratio and a risk that states in the event EC-X savings are less than “insert your value here” additional nodes will need to be purchased.
Tip: Always size for at least N+1 at the capacity layer, meaning if your largest node is 10TB RAW and with EC-X and RF2 you expect to have for example 7.5TB usable, that your container is configured with an “Advertised Capacity” at least N-1 capacity of the storage pool. (Or N-2 for clusters using RF3)
I hope you find this helpful when sizing your Nutanix environments.