
I saw the below picture posted on Twitter, and there has been some discussion around the de-duplication ratio (shown below as an an amazing 28.4:1) and what this should and should not include.
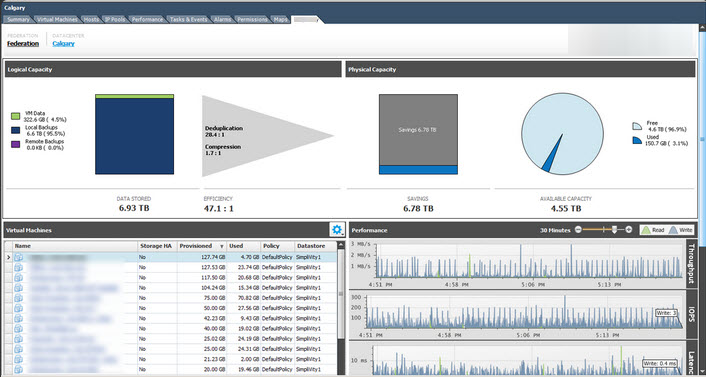
In the above case, this ratio includes VM snapshots or what some people in my opinion incorrectly refer to as “backups” (But that’s a topic for another post). In other storage solutions, things like savings from intelligent cloning may also be included.
First l’d like to briefly explain what de-duplication means to me.
I think the below diagram really sums it up well. If 12 pieces of data exist (ie: Have been written or are in the process of being written in the case of in-line de-duplication) to the storage layer, de-duplication (in-line or post process) removes the duplicate data and uses pointers to direct duplicates back to a single copy rather than storing duplicates.
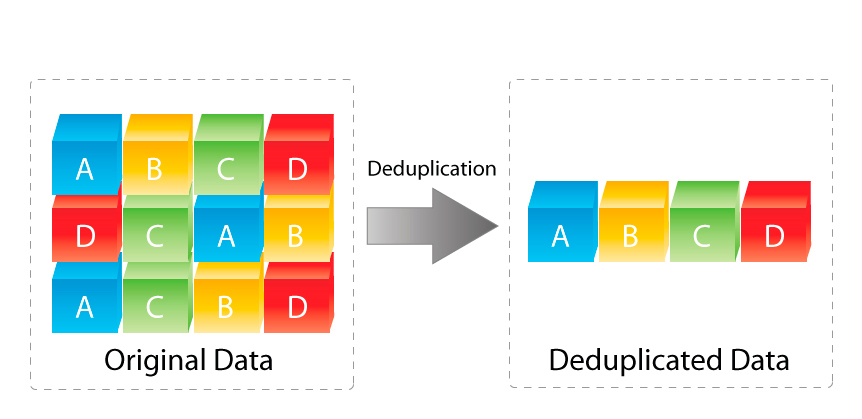
The above image is courtesy of www.enterprisestorageguide.com.
In the above example, the original data has 12 blocks which have been de-duplicated down to 4 blocks.
With this in mind, what should be included in the de-duplication ratio?
The following are some ways to reduce data consumption which in my opinion add value to a storage solution:
1. De-duplication (In-line or post process)
2. Intelligent cloning i.e.: Things like VAAI-NAS Fast File Clone, VCAI, FlexClone etc
3. Point in time snapshot recovery points. (As they are not backups until stored elsewhere)
Obviously, if data that exists or is being written to a storage system and its de-duplicated in-line or post process, this data reduction should be included in the ratio. I’d be more than a little surprised if anyone disagreed on this point.
The one exception to this is where VMDKs are Eager Zeroed Thick (EZT) and de-duplication is simply removing 0’s which in my opinion is simply putting additional load on the storage controllers and over inflating the de-duplication ratio when thin provisioning can be used.
For storage solutions de-duplicating zeros from EZT VMDKs, these capacity savings should be called out as a separate line item. (Discussed later in this post).
What about Intelligent cloning? Well the whole point of intelligent cloning is not to write or have the storage controllers process duplicate data in the first place. So based on this, VMs which are intelligently cloned are not deduped as duplicate data is never written or processed.
As such its my opinion Intelligent cloning savings should not be included in the de-duplication ratio.
Next lets talk “point in time snapshot recovery points“.
The below image shows the VM before a snapshot (a.) has blocks A,B,C & D.
Then after a snapshot without modifications, the VM has the same blocks A,B,C & D.
Then finally, when the VM makes modifications to or deletes data after the snapshot, we see the A,B,C & D remain in tact thanks to the snapshot but then we have a deleted item (B) then modified data (D+) along with net new data E1 & E2.
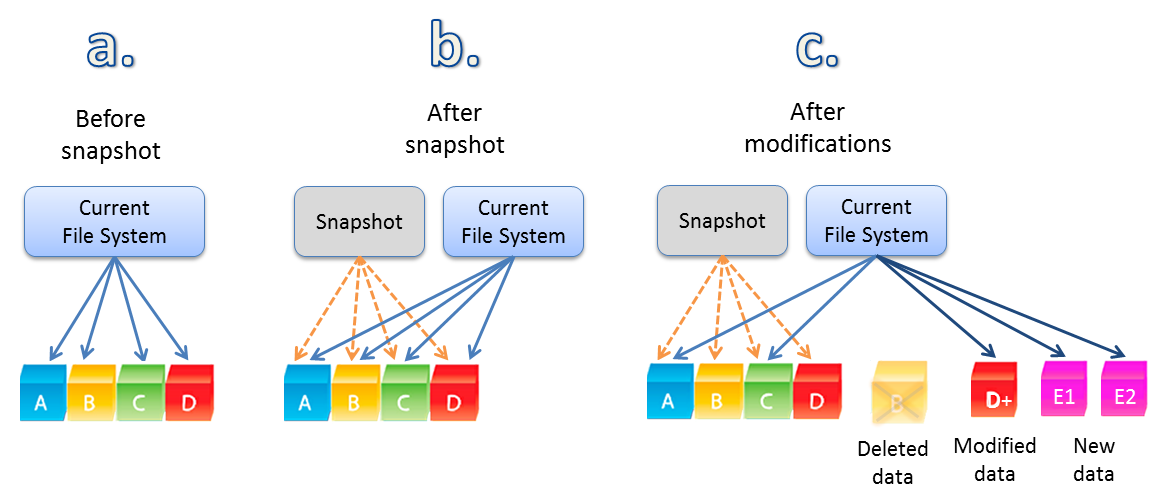
Image courtesy of www.softnas.com.
So savings from snapshots are also not “de-duplicating” data, they are simply preventing new data being written, much like intelligent cloning.
As with Intelligent cloning savings, my opinion is savings from snapshots should not be included in the de-duplication ratio.
Summary
In my opinion, the de-duplication ratio reported by a storage solution should only include data which has been written to disk (post process), or was in the process of being written to disk (in-line) that has been de-duplicated.
But wait there’s more!
While I don’t think capacity savings from Intelligent cloning and snapshots should be listed in the de-duplication ratio, I think these features are valuable and the benefits of these technologies should be reported.
I would suggest a separate ratio be reported, for example, Data Reduction.
The Data reduction ratio could report something like the following where all capacity savings are broken out to show where the savings come from:
1) Savings from Deduplication: 2.5:1 (250GB)
2) Savings from Compression: 3:1 (300GB)
3) Savings from Intelligent Cloning: 20:1 (2TB)
4) Savings from Thin Provisioning: 50:1 (5TB)
5) Savings from Point in time Snapshots: 30:1 (3TB)
6) Savings from removal of zeros in EZT VMDKs: 100:1 (10TB)
Then the Total data reduction could be listed e.g.: 60.5:1 (20.7TB)
For storage solutions, the effective capacity of each storage tiers (Memory/SSD/HDD) for example could also be reported as a result of the data reduction savings.
This would allow customers to compare Vendor X with Vendor Y’s deduplication or compression benefits, or compare a solution which can intelligently clone with one that cannot.
Conclusion:
The value of deduplication, point in time snapshots and intelligent cloning in my mind are not in question, and I would welcome a discussion with anyone who disagrees.
I’d hate to see a customer buy product “X” because it was advertised to have a 28.4:1 dedupe ratio and then find they only get 2:1 because they don’t for example take 4 hourly snapshots of every VM in the environment.
The point here is to educate the market on what capacity savings are achieved and how so customers can compare apples with applies when making purchasing decisions for datacenter infrastructure.
As always, feedback is welcomed.
*Now I’m off to check what Nutanix reports as de-duplication savings. 🙂