
HPE have been relentless with their #HPEDare2Compare twitter campaign focused on the market leading Nutanix Enterprise Cloud platform and I for one have had a good laugh from it. But since existing and prospective customers have been asking for clarification I thought I would do a series of posts addressing each claim.
In part of this series, I will respond to the claim (below) that Nutanix can’t guarantee at least a 10:1 data efficiency ratio.
Firstly let’s think about what is being claimed by HPE/SVT.
If you’re a potential customer, it would be fair for you to assume that if you have 100TB on your current SAN/NAS and you purchase HPE/SVT, you would only need to buy 10TB plus some room growth or to tolerate failures.
But this couldn’t be further from the truth. In fact, if you have 100TB today, you’ll likely need to purchase a similar capacity of HPE/SVT as most platform, even older/legacy ones have some data efficiency already, so what HPE/SVT is offering with deduplication and compression is nothing new or unique.
Let’s go over what the “HyperGuarantee” states and why it’s not worth the paper it’s written on.

It sounds pretty good, but two things caught my eye. The first is “relative to comparable traditional solutions” which excludes any modern storage which has this functionality (such as Nutanix) and the words “across storage and backup combined”.
Let’s read the fine print about “across storage and backup combined”.

Hold on, I thought we were talking about a data reduction guarantee but the fine print is talking about a caveat requiring we configure HPE/Simplivity “backups”?
The first issue is if you use an enterprise backup solution such as Commvault, or SMB plays such as Veeam? The guarantee is void and with good reason as you will (HPE)discover shortly. 😉
Let’s do the math on how HPE/SVT can guarantee 10:1 without giving customers ANY real data efficiency compared to even legacy solutions such as Netapp or EMC VNX type platforms.
- Let’s use a single 1 TB VM as a simple example.
- Take 30 snapshots (1 per day for 30 days) and count each snapshot as if it was a full “backup” to disk.
- Data stored now equals 31TB (1 TB + 30 TB)
- Actual Size on Disk is only ~1TB (This is because snapshots don’t create any copies of the data)
- Claimed Data Efficiency is 31:1
- Effective Capacity Savings = 96.8% (1TB / 31TB = 0.032) which is rigged to be >90% every time
So the guarantee is satisfied by default, for every customer and without actually providing data efficiency for your actual data!
I have worked with numerous platforms over the years, and the same result could be guaranteed by Netapp, Dell/EMC, Nutanix and many more. In my opinion the reason these vendors don’t have a guarantee is because this capability has long been table stakes.
Let’s take a look at a screenshot of the HPE/SVT interface (below).
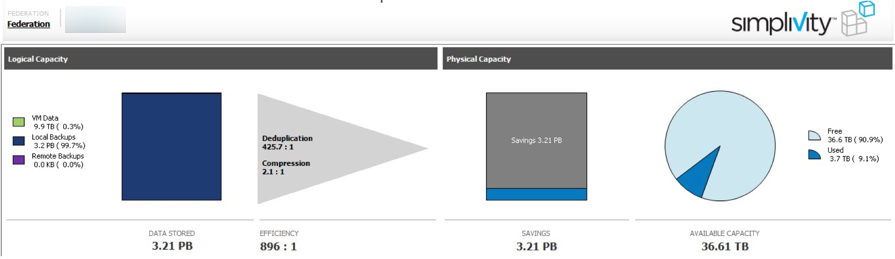
Source of image us an official SVT case study which can be found at: https://www.simplivity.com/case-study-coughlan-companies/
It shows an efficiency of 896:1 which again sounds great, but behind the smoke and mirrors it’s about as misleading as you can get.
Firstly the total “VM data” is 9.9TB
The “local backups” which are actually just pointer based copies (not backups at all) reports 3.2PB.
Note: To artificially inflate the report “deduplication” ratio, simply schedule more frequent metadata copies (what HPE/SVT incorrectly refer to as “backups”) and the ratio will increase.
The “remote backups” funnily enough are 0.0Kb which means the solution actually has no backups.
The real data reduction ratio can be easily calculated by taking the VM data of 9.9TB and dividing that by the “Used” capacity of 3.7TB which equates to 2.67:1 which can be broken down to be 2:1 compression as shown in the GUI with a <1.5:1 deduplication ratio.
In short, the 10:1 data efficiency HyperGuarantee is not worth the paper it’s written on, especially if you’re using a 3rd party backup product. If you choose to use the HPE/SVT built in pointer based option with or without replication, you will see the guaranteed efficiency ratio but don’t be fooled into thinking this is something unique to HPE/SVT as most other vendors including Nutanix have the same if not better functionality.
Remember, other vendors including Nutanix do not report metadata copies as “backups” or “data reduction” because its not.
So ask your HPE/SVT rep: “How much deduplication and compression is guaranteed WITHOUT using their pointer based “backups”. The answer is NONE!
For more information read this article which has been endorsed by multiple vendors on what should be included in data reduction ratios.
Return to the Dare2Compare Index: