For a long time, it has been widely considered that thick provisioning is required to achieve maximum storage performance and for many years this was a good rule of thumb.
Before we get into details, what are Thick and Thin provisioning?
Thick provisioning is where storage allocated to a LUN, NFS mount or Virtual Disk (such as a VMDK in ESXi, VHDX in Hyper-V or vDisk in AHV) is zeroed out and/or fully reserved regardless of how much capacity is actually used.
Thick provisioning avoids a storage subsystem from having to zero out a block before writing new data which is one of the reasons higher performance could be achieved on many storage platforms.
Thin provisioning on the other hand is where storage allocated to a LUN or Virtual Disk is zeroed as data is written and allows physical capacity to be overcommitted.
The advantages of Thick provisioning included easier capacity management, or simply put a “What you see is what you get” as well as maximum performance on most platforms. But by maximum performance, even on older storage platforms the advantage was rarely significant as people would claim.
VMware conducted a Performance Study of VMware vStorage Thin Provisioning back in the ESXi 4.0 days (~2009) which I will briefly summarise.
On page 6 of the performance study the following graph shows the different in performance between Thin and Thick VMDKs during zeroing and post-zeroing.

As you can see the performance is almost identical.
The disadvantages though were and remain significant to this day which include an inability to overcommit storage, meaning physical free space has to be maintained at multiple layers such as RAID group, LUN, Virtual Disk layers, leading to inefficiency.
The advantages of Thin provisioning include the ability to overcommit storage which results in more flexibility when sizing LUNs & Virtual Disks and less wasted space. The only real downsides were potentially increased capacity management complexity and lower performance.
I have previously written two example architectural decisions regarding using “Thin on Thin“, meaning thin provisioned virtual disks on a thin provisioned LUN or NFS mount as well as “Thin on Thick” meaning thin provisioned virtual disks on a thick provisioned LUN or NFS mount. These two examples cover off many of the traditional pros and cons between thick and think, so I won’t repeat myself here.
I never wrote an example design decision for Thick on Thick, but this was common practice when provisioning storage was time consuming, difficult and involved lengthly delays to engage subject matter experts.
In early 2015, I wrote a two part blog series where I explained it’s not as simple as you might think to calculate usable capacity where I compared SAN/NAS verses Nutanix. In part 1, I highlight that the LUN Provisioning Type is one area which can greatly impact the usable capacity of a traditional storage platform.
But fast forward into the era of hyper-converged platforms like Nutanix and some modern storage arrays and the major downsides of thin provisioning, being complexity of capacity management and reduced performance have not only been reduced, but at least in the case of Nutanix, have been eliminated all together.
Let’s address Capacity management w/ Nutanix:
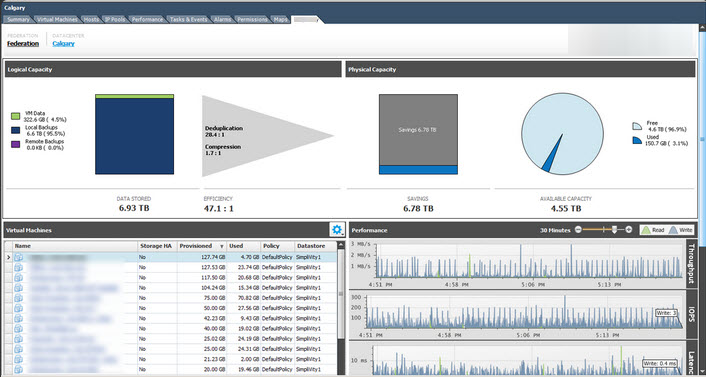
Storage utilisation only needs to be monitored in ONE place, the storage summary which lives on the home screen of the Nutanix HTML 5 UI.

No matter how many nodes in your cluster, number of containers (which translate to datastores in a VMware environment), virtual machines & virtual disks or physical servers connecting via ABS, this is the only place you need to monitor capacity.
There are no RAID groups, Disk Groups, Aggregates, LUNs etc where capacity needs to be managed. All nodes in a cluster contributed to the capacity of the cluster and even when one or more virtual machines use more capacity than a the node they run on, Nutanix Acropolis Distributed Storage Fabric (ADSF) takes care of it.
So issue #1, Capacity management, is solved. Now it’s onto the issue of performance.
Thin Provisioning Performance w/ Nutanix:
When running ESXi, Nutanix runs NFS datastores and supports thick provisioning via the VAAI-NAS Space reservation primitive as discussed in this post. This allows the creation of thick provisioned (Eager Zero or Lazy Zero Thick) VMDKs when traditionally NFS datastores did not support it.
However this was only required for Oracle RAC and VMware Fault Tolerance and was not a performance requirement.
However from a performance perspective, Thin provisioning actually outperforms thick on intelligent storage such as Nutanix. In the specific case of Nutanix, random write I/O is serviced by the fastest tier available (e.g.: SSD) and via the operations log (OPLOG) which takes the random writes commits them to persistent media, and then coalesces them into sequential IO to then commit to SSD before tiering it off to lower cost storage in the case of hybrid nodes.
This means the write penalty for overwriting or zeroing blocks before writing new I/O is eliminated.
In fact if you configure thick provisioned virtual disks, as the zeros (or whitespace) is being written by the hypervisor, the Nutanix storage fabric acknowledges every I/O and discards the zeros in favour of storing metadata and simply reserving the capacity. In simple terms, this just means Nutanix has to acknowledge a whole bunch of nothing and the thick provisioning is achieve with a simple reservation as opposed to zeroing out many GBs or TBs of storage.
This means thick provisioning is actually lower performance than thin provisioning on Nutanix.
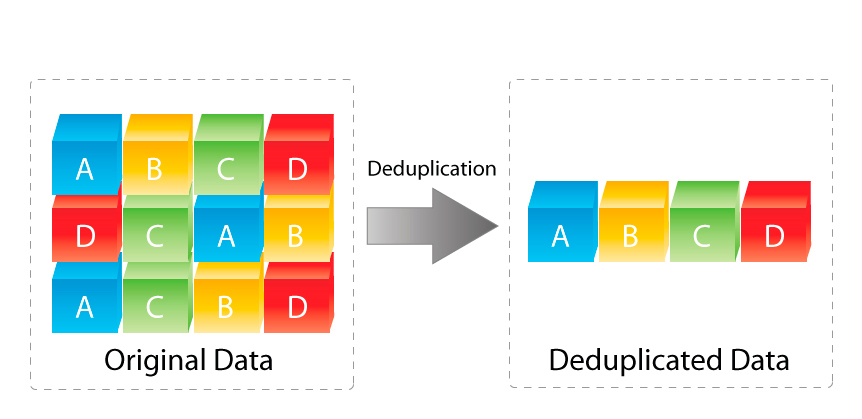
With modern, intelligent storage, there is limited if any benefits to using thick provisioning, the only example I can think of is to artificially inflate the deduplication ratio as thick provisioned virtual disks tend to have a lot of zeros all of which dedupe. I wrote an article titled: “Deduplication ratios – What should be included in the reported ratio?” which covers off this point in detail but in short, don’t create unnessasary data (in this case, zeros) just to inflate your dedupe ratio, it just wastes storage controller resources and achieves no additional benefits.
The following is a comprehensive list of the real world advantages of using thick provisioning on Nutanix.
This space is intentionally left blank
Summary:
For the best efficiency and performance when deploying virtual machines or storage for physical servers via ABS on Nutanix, use thin provisioning!