I recently wrote Nutanix AOS 5.5 delivers 1M IOPS from a single VM, but what happens when you vMotion which showed the impact of a vMotion was around -10% for a period of approx. 3 seconds before read performance resumed back to pre-migration levels.
In this post I will be addressing the question about performance for a single VM with a more realistic 70% read, 30% write IO profile which was performed using an 8k IO size and what the impact is during and after a live migration.
While not surprising to Nutanix customers, this result shows a maximum starting baseline of 436K random read and 187k random write IOPS and immediately following the migration performance reduced to 359k read and 164k write IOPS before achieving greater performance than the original baseline @ 446k read and 192k IOPS within a few seconds.
So in comparison to 100% random read which achieved just over 1 million 8k IOPS, the 70/30 mix achieves in the ballpark of 600k IOPS which is very respectable. Not bad for a platform which Nutanix competitors continue to describe as only being good for VDI. Considering even the largest array from a leading all flash SAN vendor is only advertising performance in the hundreds of thousand random read range, it shows Nutanix unique hyper-converged architecture can achieve higher performance than a monolithic all flash array from a single VM.
This shows that with the unique Nutanix Acropolis Distributed Storage Fabric, very high performance at low latency can be achieved with real world IO patterns even during and after live migrating the virtual machine across a distributed platform.
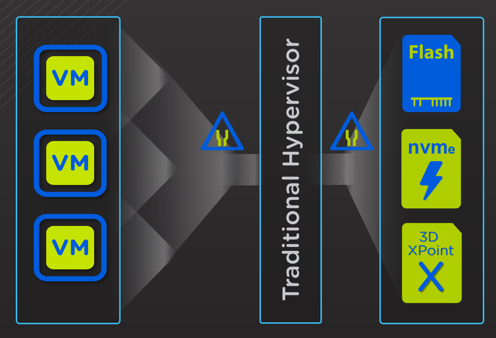
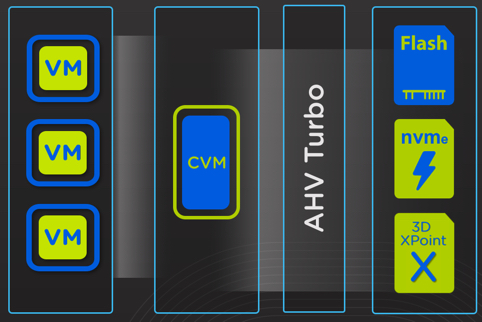
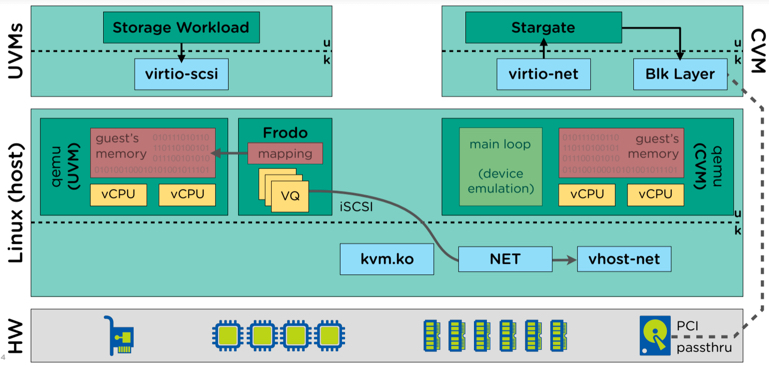
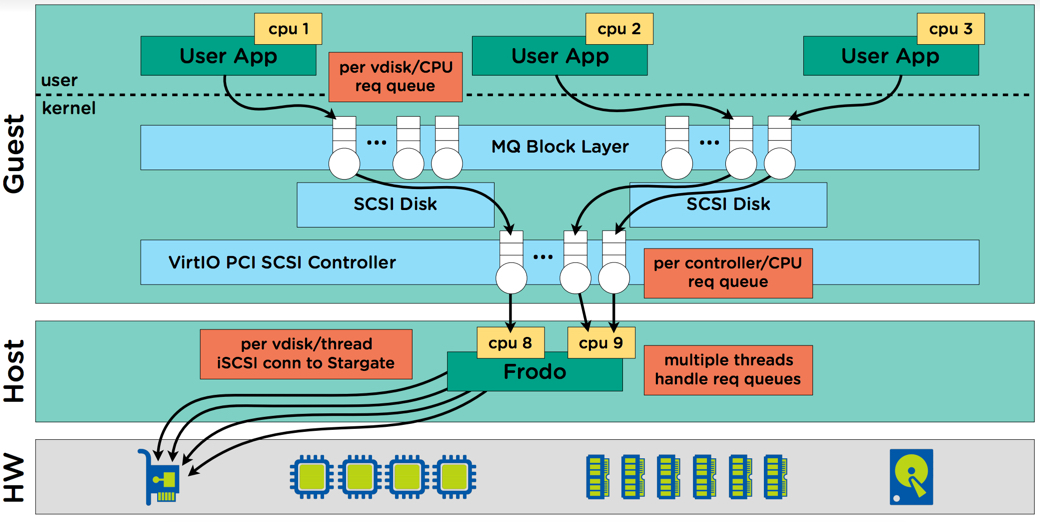
This result is further evidence of the efficiency of Nutanix Acropolis Hypervisor, AHV (which is included at no additional charge with AOS) as well as the IO path running in user space (not the much hyped in-kernel). This is in part thanks to AHV Turbo Mode which optimised the IO path which was announced at .NEXT 2017 in Washington. In addition to these excellent levels of performance, they can be sustained even when using data protection features such as snapshots as shown in recent post I wrote about Nutanix X-ray tool where I used the Snapshot impact scenario to compare Nutanix AHV and a leading hypervisor and SDS product. If you don’t have time to read the post, in short, the Nutanix competitors performance degraded as snapshots were taken while Nutanix AHV’s performance remained consistent which is essential for real world scenarios, especially with business critical applications.
With Nutanix unique ability to scale out performance using storage only nodes, even higher performance can be achieved without modification to the virtual machine to applications which gives Nutanix further advantage over the competition.
Nutanix data locality ensures optimal performance by ensuring new data is always local to the VM and cold data can remain remote indefinitely while only hot data will be migrated locally if/when required at a 1MB granularity. This translates to intelligent data locality and not brute force locality as it is frequently mistaken to be.
Back to Part 1