Over the last few years, I’ve had numerous customers ask about how Nutanix can support bare metal workloads. Up until recently, I haven’t had an answer the customers have wanted to hear.
As a result, some customers have been stuck using their exisiting SAN or worse still being forced to go out and buy a new SAN.
As a result many customers who have wanted to use or have already deployed hyperconverged infrastructure (HCI) for all other workloads are stuck managing an all flash array silo to service some bare metal workloads.
In June at .NEXT 2016, Nutanix announced Acropolis Block Services (ABS) which now allows bare metal workloads to be serviced by new or existing Nutanix clusters.

As Nutanix has both hybrid (SSD+SATA) and all-flash nodes, customers can chose the right node type/s for their workloads and present the storage externally for bare metal workloads while also supporting Virtual Machines and Acropolis File Services (AFS) and containers.
So why would anyone buy an all-flash array? Let’s discuss a few scenarios.
Scenario 1: Bare metal workloads
Firstly, what applications even need bare metal these days? This is an important question to ask yourself. Challenge the requirement for bare metal and see if the justifications are still valid and if so, has anything changed which would allow virtualization of the applications. But this is a topic for another post.
If a customer only needs new infrastructure for bare metal workloads, deploying Nutanix and ABS means they can start small and scale as required. This avoids one of the major pitfalls of having to size a monolithic centralised, dual controller storage array.
While some AFA vendors can/do allow for non-disruptive controller upgrades, it’s still not a very attractive proposition, nor is it quick or easy. and reduces resiliency during the process as one of two controllers are offline. Nutanix on the other hand performs one click rolling upgrades which mean the largest the cluster, the lower the impact of an upgrade as it is performed one node at a time without disruption and can also be done without risk of a subsequent failure taking storage offline.
If the environment will only ever be used for bare metal workloads, no problem. Acropolis Block Services offers all the advantages of an All Flash Array, with far superior flexibility, scalability and simplicity.
Advantages:
- Start small and scale granularly as required allowing customers to take advantage of newer CPU/RAM/Flash technologies more frequently
- Scale performance and capacity by adding node/s
- Scale capacity only with storage-only nodes (which come in all flash)
- Automatically scale multi-pathing as the cluster expands
- Solution can support future workloads including multiple hypervisors / VMs / file services & containers without creating a silo
- You can use Hybrid nodes to save cost while delivering All Flash performance for workloads which require it by using VM flash pinning which ensures all data is stored in flash and can be specified on a per disk basis.
- The same ability as an all flash array to only add compute nodes.
Disadvantages:
- Your all-flash array vendor reps will hound you.
Scenario 2: Mixed workloads inc VMs and bare metal
As with scenario 1, deploying Nutanix and ABS means customers can start small and scale as required. This again avoids the major pitfall of having to size a monolithic centralised, dual controller storage array and eliminates the need for separate environments.
Virtual machines can run on compute+storage nodes while bare metal workloads can have storage presented by all nodes within the cluster, including storage-only nodes. For those who are concerned about (potential but unlikely) noisy neighbour situations, specific nodes can also be specified while maintaining all the advantages of Nutanix one-click, non-disruptive upgrades.
Advantages:
- Start small and scale granularly as required allowing customers to take advantage of newer CPU/RAM/Flash technologies more frequently
- Scale performance and capacity by adding node/s
- Scale capacity only with storage-only nodes (which also come in all flash)
- Automatically scale multi-pathing for bare metal workloads as the cluster expands
- Solution can support future workloads including multiple Hypervisors / VMs / file services & containers without creating a silo.
Disadvantages:
- Your All-Flash array vendor reps will hound you.
What are the remaining advantages of using an all flash array?
In all seriousness, I can’t think of any but for fun let’s cover a few areas you can expect all-flash array vendors to argue.
Performance
Ah the age old appendage measuring contest. I have written about this topic many times, including in one of my most popular posts “Peak performances vs Real world performance“.
The fact is, every storage product has limits, even all-flash arrays and Nutanix. The major difference is that Nutanix limits are per cluster rather than per Dual Controller Pair, and Nutanix can continue to scale the number of nodes in a cluster and continue to increase performance. So if ultimate performance is actually required, Nutanix can continue to scale to meet any performance/capacity requirements.
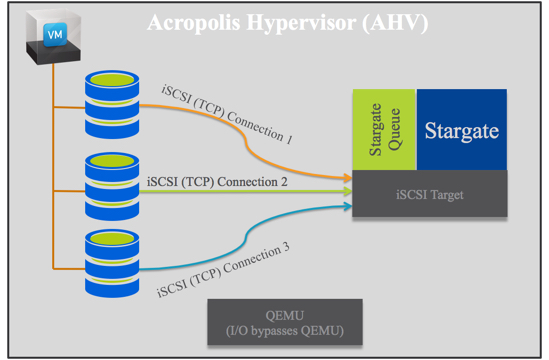
In fact, with ABS the limit for performance is not even at the cluster layer as multiple clusters can provide storage to the same bare metal server/s while maintaining single pane of glass management through PRISM Central.
I recently completed some testing with where I demonstrated the performance advantage of storage only nodes for virtual machines as well as how storage-only nodes improve performance for bare metal servers using Acropolis Block Services which I will be publishing results for in the near future.
Data Reduction
Nutanix has had support for deduplication, compression for a long time and introduced Erasure Coding (EC-X) mid 2015. Each of these technologies are supported when using Acropolis Block Services (ABS).
As a result, when comparing data reduction with all-flash array vendors, while the implementation of these data reduction technologies varies between vendors, they all achieves similar data reduction ratios when applied to the same dataset.
Beware of some vendors who include things like backups in their deduplication or data reduction ratios, this is very misleading and most vendors have the same capabilities. For more information on this see: Deduplication ratios – What should be included in the reported ratio?
Cost
Here we should think about what are the age old problems are with centralized shared storage (like AFAs)? Things like choosing the right controllers and the fact when you add more capacity to the storage, you’re not (or at least rarely) scaling the controller/s at the same time come to mind immediately.
With Nutanix and Acropolis Block Services you can start your All Flash solution with three nodes which means a low capital expenditure (CAPEX) and then scale either linearly (with the same node types) or non-linearly (with mixed types or storage only nodes) as you need to without having to rip and replace (e.g.: SAN controller head swaps).
Starting small and scaling as required also allows you to take advantage of newer technologies such as newer Intel chipsets and NVMe/3D XPoint to get better value for your money.
Starting small and scaling as required also minimizes – if not eliminates – the risk of oversizing and avoids unnecessary operational expenses (OPEX) such as rack space, power, cooling. This also reduces supporting infrastructure requirements such as networking.
Summary:
As shown below, the Nutanix Acropolis Distributed Storage Fabric (ADSF) can support almost any workload from VDI to mixed server workloads, file, block , big data, business critical applications such as SAP / Oracle / Exchange / SQL and bare metal workloads without creating silos with point solutions.

In addition to supporting all these workloads, Nutanix ADSF scalability both from a capacity/performance and resiliency perspective ensures customers can start small and scale when required to meet their exact business needs without the guesswork.
With these capabilities, the All-Flash array is obsolete.
I encourage everyone to share (constructively) your thoughts in the comments section.
Note: You must sign in to comment using WordPress, Facebook, LinkedIn or Twitter as Anonymous comments will not be approved,
Related Articles:
-
Things to consider when choosing infrastructure.
-
Scale out performance testing with Nutanix Storage Only Nodes
-
What’s .NEXT 2016 – Acropolis Block Services (ABS)
-
Scale out performance testing of bare metal workloads on Acropolis Block Services (Coming soon)
-
What’s .NEXT 2016 – Any node can be storage only
- What’s .NEXT 2016 – All Flash Everywhere!