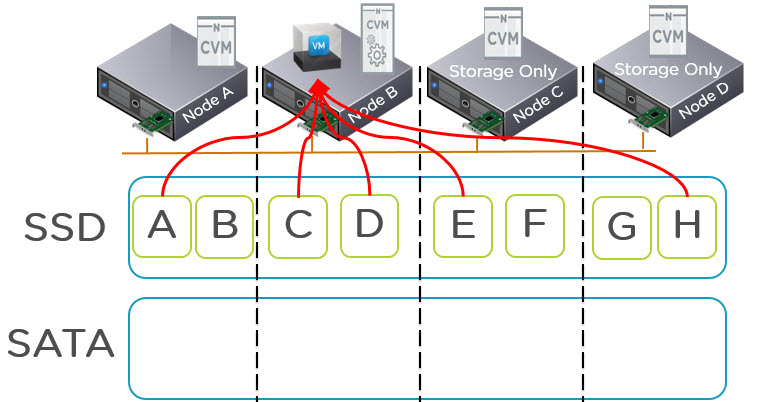
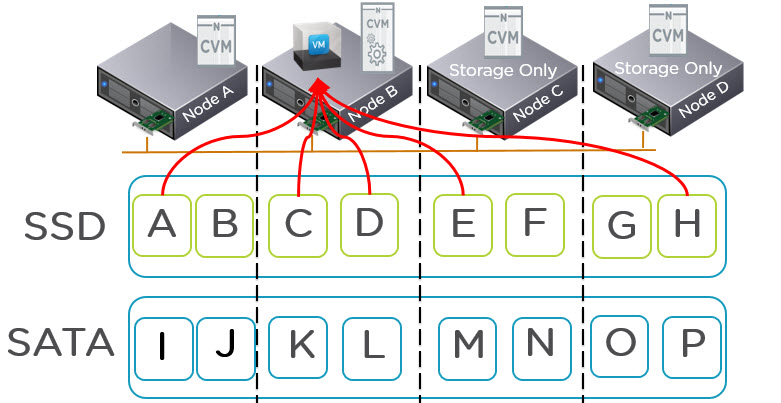
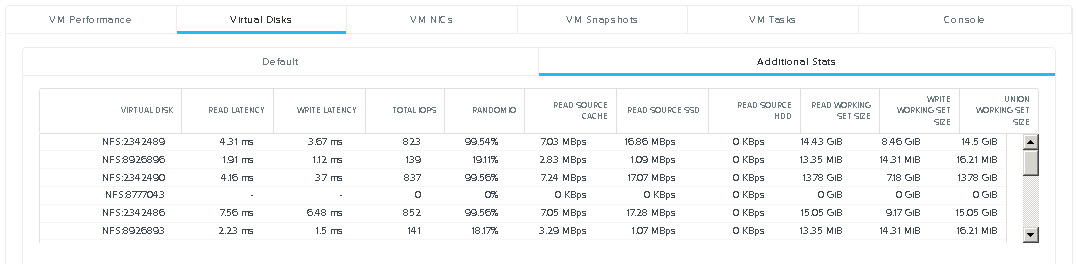
Before I go into the details of why Acropolis Hypervisor (AHV) is the next generation of hypervisor, I wanted to quickly cover what the Xtreme Computing Platform is made up of and clarify the product names which will be discussed in this series.
In the below picture we can see Prism which is a HTML 5 based user interface sits on top of Acropolis which is a Distributed Storage and Application Mobility across multi-hypervisors and public clouds.
At the bottom we can see the currently support hardware platforms from Supermicro and Dell (OEM) but recently Nutanix has announced an OEM with Lenovo which expands customer choice further.
Please do not confuse Acropolis with Acropolis Hypervisor (AHV) as these are two different components, Acropolis is the platform which can run vSphere, Hyper-V and/or the Acropolis Hypervisor which will be referred to in this series as AHV.

I want to be clear before I get into the list of why AHV is the next generation hypervisor that Nutanix is a hypervisor and cloud agnostic platform designed to give customers flexibility & choice.
The goal of this series is not trying to convince customers who are happy with their current environment/s to change hypervisors.
The goal is simple, to educate current and prospective customers (as well as the broader market) about some of the advantages / values of AHV which is one of the hypervisors (Hyper-V, ESXi and AHV) supported on the Nutanix XCP.
Here are my list of reasons as to why the Nutanix Xtreme Computing Platform based on AHV is the next generation hypervisor/management platform and why you should consider the Nutanix Xtreme Computing Platform (with Acropolis Hypervisor a.k.a AHV) as the standard platform for your datacenter.
Why Nutanix Acropolis hypervisor (AHV) is the next generation hypervisor
Part 2 – Simplicity
Part 3 – Scalability
Part 4 – Security
Part 5 – Resiliency
Part 6 – Performance
Part 7 – Agility (Time to Value)
Part 8 – Analytics (Performance & Capacity Management)
Part 9 – Functionality (Coming Soon)
Part 10 – Cost
NOTE: For a high level summary of this series, please see the accompanying post by Steve Kaplan, VP of Client Strategy at Nutanix (@ROIdude)