This is a perfect example of DeepStorage trying to highlight the strengths of only one favored (and sponsored) product.
Data Reduction
DeepStorage makes several claims here which are simply factually incorrect.
Compression and deduplication are more recent additions to the Nutanix distributed system…
I’ve been working at Nutanix now since 2013 and deduplication and compression have been part of the product since then; they are certainly not recent additions! Erasure Coding (EC-X), announced at .NEXT 2015, is the most recent data efficiency addition to the platform however it is fair to say the data reduction capabilities have evolved over time to provide better data reduction, lower overheads and higher performance.
I am particularly pleased that DeepStorage has raise the following point:
Note that Nutanix employees downplay their data reduction; one Nutanix blogger recommending that customers size systems without factoring in data reduction and take any savings as gravy.
DeepStorage correctly points out that Nutanix tends to downplay our Data reduction, but this tendency results from a customer-first vision of “undersell and over-deliver.” I believe that DeepStorage “one Nutanix blogger” reference is likely me. While I am a big fan of data reduction and avoidance technologies, I also hate that these features have become what I consider extremely overrated/oversold. I have seen countless customers burnt by vendors promoting high data efficiency ratios, in fact I have written “Sizing infrastructure based on vendor Data Reduction assumptions,” which highlights the risks associated with making assumptions around vendor data reduction and concludes by saying:
“While data reduction is a valuable part of a storage platform, the benefits (data reduction ratio) can and do vary significantly between customers and datasets. Making assumptions on data reduction ratios even when vendors provide lots of data showing their averages and providing guarantees, does not protect you from potentially serious problems if the data reduction ratios are not achieved.”
I stand by these comments, and prefer to size customer environments based on their requirements with a “start small and scale if/when required” approach while using conservative data reduction estimates, such as 1.5:1. I then provide the customer with a scalable solution and repeatable model addressing different scenarios e.g.: Capacity scaling increments. If the customer’s dataset achieves a higher than expected reduction ratio – fantastic. They have more room for growth. If it doesn’t, the customer is not put in a risky position as the article I referenced highlights.
The “start small and scale” approach requires a highly scalable platform which can start small and scale as required without rip and replace. It should furthermore scale fractionally rather than requiring large incremental purchases. Nutanix, of course, epitomises this fractional consumption model while, surprise surprise, Pure Storage and other traditional SAN vendors do not. This is probably why they oversell the benefits of data reduction.
DeepStorage goes on to make several more claims including:
First, a Pure FlashArray deduplicates all the data written to it as a single deduplication realm, uses deduplication block sizes as small as 512 bytes and uses a multi-stage compression mechanism, all of which will lead to very efficient reduction.
Nutanix, by comparison, uses 16KB deduplication blocks to deduplicate data across a container or datastore. Nutanix clusters with multiple containers will constitute multiple deduplication realms with data deduplicated within each realm but not across realms. As for compression, Nutanix uses a slightly less aggressive method, trading storage efficiency for CPU efficiency.
Nutanix announced Enhanced & Adaptive (multi-stage) Compression back at .NEXT in 2016 which, as per the referenced article, provides:
- Higher compression savings
- Lower CVM overheads
- Dramatically reduced background file system maintenance tasks
The above benefits were included in the following major AOS upgrade. And the Nutanix one-click non-disruptive upgrades enabled customers to quickly take advantage of these enhancements without touching their existing nodes – regardless of geographic location or age.
I challenge the DeepStorage statement “As for compression, Nutanix uses a slightly less aggressive method, trading storage efficiency for CPU efficiency.” as the data reduction ratios as well as performance from Nutanix dual stage compression have been excellent. I published an article in February 2017 “What is the performance impact & overheads of Inline Compression on Nutanix?” which shows the following side-by-side comparison with compression off (left) and on (right) where the IOPS, throughput, latency AND CVM CPU usage remain almost exactly consistent.

Regarding deduplication realms, customers can choose to have a single realm which provides truly global deduplication across an entire Nutanix cluster or be able to utilize separate boundaries where required. For example: multi-tenant environments or business critical applications such as SQL Always on or MS Exchange DAGs frequently have requests or requirements to ensure separation of data which can be achieved, if required, on Nutanix.
When it comes to the granularity of deduplication, 512bytes will achieve a higher ratio than say 4 or 8k, but at that point you are at, or past, the stages of diminishing returns. The overheads continue to increase. So the flip side of the argument is the more granular your deduplication, the higher your overheads can be.
This is one reason why Pure Storage’s capacity scalability is much less than that of a Nutanix environment.
On the topic of realms, with Nutanix file and block storage is natively supported on the one cluster leading to higher efficiency rates (less waste) and with ability to have a single realm (or global) deduplication, means that Nutanix efficiency works across both file and block storage.
Pure Storage has different physical products for File and Block storage, which typically leads to inefficiency and the global deduplication which DeepStorage is highlighting, now has two realms not one.
Real World Data reduction rates
DeepStorage makes the claim:
we tried to approximate real world data reduction rates.
I stand by the statement I have made many times over the years that deduplication is the most overrated functionality in the storage industry, if not the IT industry as a whole.
VDI deduplication ratios, in a Nutanix environment, are possibly the least relevant of any use case. Intelligent cloning allows virtual desktops to be deployed extremely fast regardless of the underlying storage type (e.g.: NVMe / SSD / SATA), and to do so in a capacity efficient manner.
You can think of this intelligent cloning process as deduplication in advance and without the overheads.
If you deployed 1,000 VDI machines each with 100GB on Nutanix using intelligent cloning, you would effectively use only 100GB as 999 of the VDI machines use metadata pointers back to the original copy. So that’s a 1000:1 data reduction ratio, without using deduplication.
Intelligent cloning savings can also be achieved in server virtualization environments by deploying new servers from templates and cloning servers for test/development. Again all these savings are achieved WITHOUT deduplication being enabled.
At this stage, I’m hoping you’re getting the sense that the DeepStorage article is overselling the advantages of data reduction to try and make the case for the article’s sponsor (Pure Storage) data reduction capabilities. While the Pure Storage data reduction capabilities are undoubtably valuable, they are unlikely to be significant purchasing decision as the delta between different vendors data reduction ratios are typically insignificant for the same dataset.
Why directly comparing data reduction ratios is foolish:
I have long been on somewhat of a mission to educate the market on data reduction ratios and how they can be extremely misleading. They are also very difficult to directly compare as Vaughn Stewart, VP of Technology at Pure Storage and I have discussed and agreed previously:
In an effort to raise awareness of this ongoing issue, back in January 2015 I published an article titled: Deduplication ratios – What should be included in the reported ratio?
I recommend you take the time to review the post before continuing with this article, but in short, Vaughn Stewart, VP of Technology at Pure Storage commented on the post with a very wise statement:
With the benefits of data reduction technologies the market does not speak the same language. This is problematic and is the core of Josh’s point – and frankly, I agree with Josh.
Now we have Vaughn and I agreeing directly comparing data reduction numbers while DeepStorage has made the mistake and claimed a higher ratio for Pure Storage without any factual data to back it.
I would like to highlight two critically important points: Deduplication ratios and Data Efficiency ratios.
Deduplication Ratios
If you are to believe DeepStorage.net:
(Pure Storage) FlashArray would reduce data twice as well as Nutanix, or 4:1 compared to Nutanix’s 2:1.
But this couldn’t be further from the truth.
There is numerous examples of Nutanix data reduction which have been posted on twitter by customers such as the following:
Here we see a saving of just under 3:1 using just compression on AOS version 5.0.1 which is now near as makes no difference two major releases old.
When deploying, for example, 1,000 VDI machines in VMware Horizon, what will the difference be in the deduplication ratio achieved by Pure Storage and Nutanix and how much usable space will be required?
In fact, the short answer is both platforms will achieve (near to the point where it makes no difference) the same capacity efficiency, but Nutanix with intelligent cloning delivers this outcome with much lower overheads both during cloning and ongoing.
The specific intelligent cloning I am referring to in this example is one of many advantages Nutanix has over products using block storage (including Pure Storage). VMware View Composer for Array Integration (VCAI), which allows Horizon to offload the creation of VDI machines to the Nutanix Acropolis Distributed Storage (ADSF) layer, delivers intelligent cloning of all the VMs and does not require deduplication (inline or post process) to achieve the capacity savings.
This means the 1,000 VDI machines are created lightning fast and with maximum space efficiency without using deduplication. Pure Storage uses deduplication to achieve the capacity savings, which in my opinion is just an unnecessary overhead when the VDI machines should just be intelligently cloned. Nutanix also doesn’t require the Pure storage controller overheads (inline or post process).
But DeepStorage.net does not let facts get in the way of a misleading justification.
Data Efficiency Ratios
Another key factor when comparing data efficiency ratios is what is included in the ratio. One very significant difference in how Pure Storage and Nutanix calculate data reduction is that Pure Storage deduplicates the zero blocks created from the Eager Zeroing VMDKs, which artificially inflates the deduplication ratio. In contrast, Nutanix simply stores metadata for zero blocks as opposed to writing and deduping them. Much like the earlier example, Nutanix simply has a more efficient way of achieving the same capacity saving outcome. Nutanix currently does not report the capacity efficiency achieved from not storing unnecessary zeros, but this will be a future enhancement to the platform to try and avoid the type of misleading comparison DeepStorage is attempting to make.
Despite the report, the DeepStorage principle actually agrees with my point as highlighted by his tweet “Zero detect isn’t dedupe.” This opinion is not reflected in the report as it does have at least some weight when it comes to questioning the real efficiency difference between the two platforms, and PureStorage is the manufacturer that paid for the report.
Data Resiliency Considerations
DeepStorage.net has again made a decision to use a configuration (RF3 + Erasure Coding) to try and make the article sponsor’s product look more favorable.
We used this hybrid RF3 with erasure coding mode when calculating the useable capacity of the Nutanix cluster. It’s the most space-efficient model Nutanix offers that provides a level of resiliency similar to the Pure FlashArray.
In the real world, Nutanix resiliency for a more capacity-efficient RF2 configuration could easily be argued to be equal, or even more resilient, than Pure Storage. When talking RF3, the resiliency of the Nutanix solution vastly exceeds that of Pure Storage.
For example, Nutanix with RF3 can sustain up to 8 concurrent node failures and up to 48 concurrent SSD/SATA drive failures.
If we take a more capacity-efficient RF2 configuration, Nutanix can still sustain up to 4 concurrent node & 24 concurrent SSD/SATA failures.
In both RF2 and RF3 configurations, Nutanix continuously monitors drive health and proactively re-protects data where drive/s are showing signs of wear or failure. Nutanix transparently reads from remote replica/s to reprotect data. This mitigates even further the chance for multiple concurrent failures to cause data unavailability or loss.
In the real world, the vast majority of Nutanix deployments, including those running business critical applications with tens of thousands of users, use RF2 which delivers excellent resiliency, performance and up to 80% usable capacity with Erasure Coding enabled.
HPE recently tried to discredit Nutanix resiliency. I rebuted their claim in detail with the post Dare2Compare Part 4 : HPE provides superior resiliency than Nutanix? I recommend this post to anyone wanting to better understand Nutanix resiliency as it covers how Nutanix protects data many different failure scenario examples.
But let’s give DeepStorage.net the benefit of the doubt and say a customer, for some reason, wants to use RF3. They can choose to do so for just the workloads that require the higher resiliency,as opposed to all data, the bulk of which is unlikely to have any real requirement to support the loss of up to 48 drives concurrently.
Regardless of workload, Nutanix data reduction applies to all replicas (2 for RF2 and 3 for RF3) to ensure maximum efficiency.
If we’re talking mixed server workloads, or business critical applications, a more importaint factor to consider is failure domains. To achieve maximum availability, multiple failure domains should be used no matter what the technology. So Two clusters using RF2 with workloads spread across the two cluster is a much higher availability solution than a single cluster with RF3 or if it existed RF5 or higher.
Workloads such as SQL Always-On Availability groups, Oracle RAC and Exchange DAGs can and should be split across clusters configured with RF2, which will deliver excellent availability, performance and without using RF3.
For VDI use cases, Thanks to Nutanix intelligent cloning capabilities, very little data needs to be stored anyway, so a 3rd copy (as opposed to 2 copies with RF2) is not a significant factor.
Let’s take this a step further and assume a 100GB golden image and assume that Nutanix shadow copies are used to give maximum performance. Even with the 2 x 960GB SSDs in a hybrid system, and the unrealistic RF3 configuration DeepStorage chose, the usable capacity of the SSD tier is 421GiB as shown below.
This easily fits an entire copy of the golden image and an almost infinite number of intelligent clones per node giving 100% local reads for maximum performance.
So as we can see, capacity is not a significant factor; even a hybrid system will provide all flash performance since all the I/O will typically be served from the SSD tier.
This also supports my earlier comment regarding using higher core count CPUs for greater density since scaling out is not required for performance OR capacity reasons.
Scaling & Capacity Calculations
DeepStorage makes the claim that four and eight node Nutanix clusters have lower usable capacity due to three-way replication.
“The smaller clusters of four and eight nodes have lower usable storage per node as they use three-way replication to protect their data. Once we reach 8 nodes, each additional node adds 9.75TB of useable capacity”
This statement is simply untrue. For the proposed RF3 configuration, a minimum of five nodes are required, so the premise of using a 4 node configuration is invalid.
While the following DeepStorage claim (on Pg 3) is actually in Nutanix’s favor from a usable capacity perspective, it’s incorrect and needs to be revised.
“As the cluster size increases Nutanix uses 6D+2P erasure coding, which is much more efficient.”
For the record, Nutanix Erasure Coding (EC-X) stripe sizes vary based on cluster size, with the optimal stripe size of 4+1 for RF2 supported in a >=6 node cluster and the optimal 4+2 stripe for RF3 supported in a >=7 node cluster. These stripe widths are only a soft limit and larger stripe widths have been tested and even used in some customer environment, 4+1 and 4+2 for RF3 are the maximum stripe widths by default.
Note: Larger stripe widths, while possible, provide diminishing returns and higher risk which is why Nutanix limits the default soft limits to 4+1 and 4+2 which achieve up to 80% usable capacity for RF2 and up to 66% usable for RF3, which for RF2. For more information please see “RF2 & RF3 Usable Capacity with Erasure Coding (EC-X)”
According to Pure Storage, its RAID-3D has a 22% overhead of raw for usable of 78%.
Data Locality and performance
As mentioned above, my response “Evaluating Nutanix’ original & unique implementation of Data Locality” to the VMware-sponsored DeepStorage report details why the points raised by DeepStorage are either not applicable to Nutanix or are insignificant factors in the real world.
Unfortunately, this latest DeepStorage report is another example of lacking an accurate understanding of how data locality works. Furthermore, it shows a lack of understanding of how storage-only nodes contribute to a cluster’s performance.
Since Nutanix relies on data locality to maintain high performance, Nutanix storage- only nodes are only used for the second or third copy of a VM’s data. Storage-only nodes provide less expensive capacity but performance will be determined by the primary node’s storage devices.
While I have responded to the previous report on Data Locality explaining how Nutanix implementation works, DeepStorage has continued spreading information which has been shown to be inaccurate. Even if DeepStorage chooses not to believe my post, it can be reasonably expected that further investigation would be undertaken before making additional comments on the topic in a formal report.
In the real world, as capacity is almost never a concern in VDI environments (thanks to intelligent cloning & data reduction), storage-only nodes are rarely, if ever, utilized in this use case but let’s discuss storage only nodes from a server or business critical application perspective.
I have written about the performance implications of storage-only nodes previously in a post titled, “Scale out performance testing with Nutanix Storage Only Nodes” showing the above statement made by DeepStorage to be incorrect. Performance is not limited to the primary node’s storage devices. Write performance, which is the most important for VDI (being that it’s typically >70% write), is improved as the cluster scales out as shown in the above post. Read performance, even for the SATA tier is also improved as reads can be serviced remotely in the event of contention.
As for the comment about performance being reliant on data locality, I refer you to a tweet I sent recently, but I made the actual statement in the tweet in 2013 at VMworld when being interviewed by VMworld.TV.
If for the fun of it, we assume a totally unrealistic and worst-case scenario where no data is local, Nutanix is now equal to Pure Storage’s BEST case scenario where 100% of their read and write I/O is not local.
Let’s turn to Operational Expenses (OPEX)
If I was trying to write an article to make a traditional (or legacy) server and storage offering sound more attractive than Nutanix, I would avoid as much as possible talking about OPEX as this is an almost universally accepted advantage of Nutanix (and some other HCI platforms). DeepStorage has deployed this exact strategy. The report even tries to position the lack of Nutanix management being built into vCenter as an efficiency disadvantage.
Nutanix purposefully avoided a dependence upon on vCenter in order to utilize a scale-out Prism management pane that is integrated into the platform. While a second browser tab may need to be opened when managing vSphere, this is inconsequential, especially when compared to benefits such as automated scaling, fail-over, self-healing, less licensing, less hardware, and so on.
DeepStorage also makes the following statement around the OPEX of the Pure/Cisco product:
As a worst case we estimate the organization deploying the Cisco/Pure solution would have to spend one person-day installing and configuring UCS Manager and perhaps as much as an hour per server per year.
Over the 3 year useful life of the proposed systems that’s 8 hours for installation and thirty-three hours of additional upgrade effort a total of forty-one hours or $20,500 at the premium
This statement has oversimplified real world OPEX in order to try and avoid discussing the major advantages Nutanix has over even what I described as the best AFA on the market. I put it to DeepStorage that no Managed Service Provider would manage the proposed or a similar solution for anywhere near that amount and that many sysadmins would be out of a job if this was even close to the truth.
With one server per each RU, the Cisco/Pure Storage solution would use at least 32RU plus the space for the storage. With Nutanix, the 32 nodes (4 per 2RU), would use just 16RU including the storage. So we’re comparing a half rack for Nutanix versus at least one full rack for Pure/Cisco. Now there’s an easily quantifiable and significant OPEX saving which is not mentioned in the DeepStorage report.
The power requirements for the Nutanix solution have also been incorrectly calculated. On Page 14 of the report, DeepStorage writes:
“Our choice of the Nutanix four-node, 2U block gave Nutanix a big advantage in density at two servers per rack unit. The Cisco C220s alone take up twice as much rack space, and the FlashArray will take up another 4-12U depending on the number of SSD shelves.The Nutanix website shows 1150W as typical consumption for the NX-3060 nodes in our comparison, while the Pure site shows a FlashArray//M50 we use in our larger configurations as using 650-1280W. Cisco’s UCS Power Calculator configured like the ones in our model use 515W at 75% utilization.”
The DeepStorage error is in calculating 1150W per NX-3060-G5 node when the official power figures stated are per block. In this example, the NX-3460-G5 supports 4 nodes per block. If we divide the 1150W per block number by the number of nodes in a block, 4, we get a typical consumption of 287.50W per node. So the Cisco servers alone use 79.13% per node more power than the Nutanix solution not to mention the additional power requirements for the Pure Storage platform.
The below is an updated graph reflecting the correct power usage for Nutanix while maintaining the numbers DeepStorage claimed for the Cisco platform being 515W per server.

The DeepStorage report has reached the conclusion below as a result of the incorrect power calculations:
“Our calculations show the FlashStack solution uses significantly less power than the Nutanix cluster. While hyperconverged systems can be more space efficient than conventional systems, they’re not necessarily more power efficient.”
Substituting the correct figures clearly shows that Nutanix uses significantly less power than the FlashStack solution and that Nutanix is also more space efficient.
At a high level, these findings are in line with what I’ve seen in the field which are typically around the 2x savings in both datacenter space and power reduction when compared to “converged infrastructure.” As Steve Kaplan puts it, “The only thing converged in converged infrastructure is the purchase order.”
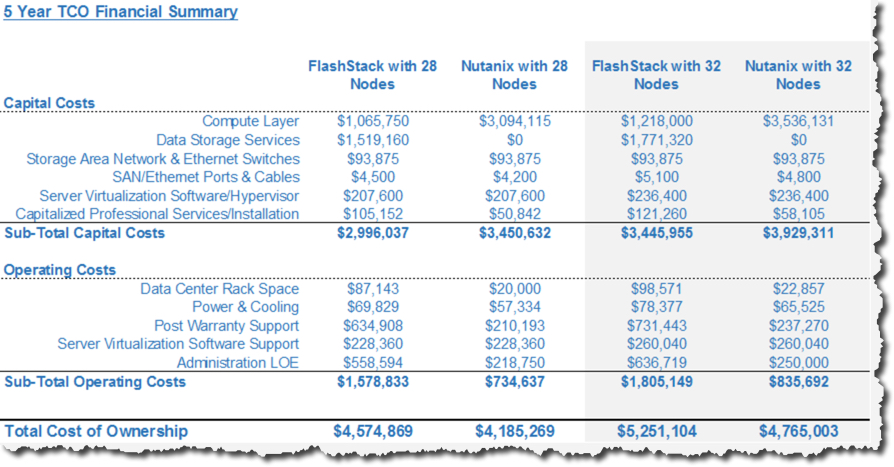
Back to focusing on the cost comparison, DeepStorage claims:
“the cost of the two systems are generally within 10% of each other.”
If we take into account only the corrected power usage, cooling (as a result of lower power usage) and the rack space savings, the 10% claimed difference, even if factual ,would likely no longer be the case. Unfortunately, I cannot validate this as DeepStorage has not included the pricing in the report from which he has formed his conclusions.
Compute Resources
DeepStorage.net has gone to some length to try and discredit the Nutanix Controller VM’s value and overstate the so called “overheads” & when combining that with the decision to use middle of the range processors, he makes a very misleading statement about CPU being the bottleneck.
Since these systems are going to run out of CPU before they run out of memory, we’re going to ignore the Nutanix VM’s memory impact.
DeepStorage goes on to state:
“Since each server/node has 48 threads and the Nutanix VM uses 8 threads the Nutanix VM consumes 1/6th of the total compute capacity of the server. To create Chart 3 below we equalized the number of CPUs available to run virtual machines by using 6 Cisco servers for every 7 Nutanix nodes. “
This statement is very misleading, as the Nutanix CVM does not consume 100% of the assigned vCPUs at all times and, even if it did, the reality is there is a Cost vs Reward for the Nutanix Controller VM (CVM). Improving storage performance reduces CPU WAIT, which reduces wasted CPU cycles, which actually INCREASES cpu efficiency for the virtual machines.
Let’s cover two examples: one VDI and one mixed server workloads.
In the context of VDI, a well sized solution, including Nutanix will in most cases run out of CPU before it runs out of memory. Let’s do a quick calculation on density to prove my point. We’ll take a NX-3460-G5 configured with E5-2695v4 [36 cores / 2.1 GHz] CPUs and 512GB RAM and assume 5% hypervisor memory overheads. One NX-3060-G5 node supports the Nutanix CVM at 8vCPUs & 32GB RAM and just under 115 Virtual Desktops w/ 2vCPUs and 4GB RAM each.
The total CPU overcommitment including the CVM is just 6.6:1 which is, in my experience, a conservative ratio delivering excellent performance for the vast majority of virtual desktop use cases. If cheaper E5-2680v4 [28 cores / 2.4 GHz] processors are used, the CPU overcommitment would increase to a still very realistic 8.5:1 ratio.
We could overcommit CPU higher, but we’ve reached the maximum RAM usage without restoring to performance impacting memory overcommitment which is rarely recommended by VDI experts these days.
As for a mixed server example, if we take the average VM sizing DeepStorage mentions of 2vCPUs and 8GB RAM, it comes down to what CPU overcommitment ratio the workload will tolerate without impacting performance. If we take 50 VMs (100vCPUs and 400GB RAM total), we are at 3:1 vCPU to pCore overcommitment and just below 90% memory utilization, again taking into account memory overheads and the CVM.
In both the VDI and server workload use cases, the compute resources assigned to the Nutanix CVM are not impacting the solution’s ability to achieve excellent and realistic density even if you do not agree the CVM improves CPU efficiency as discussed earlier.
As such, I reject the premise that the Pure/Cisco solutions only requires 6 Cisco servers for every 7 Nutanix nodes as DeepStorage claims.
This brings us nicely onto our next topic, performance.
Performance
DeepStorage highlighted the performance characteristics of the two systems at 200K and 270K respectively and stated that customers can upgrade from the lower end to the high(er) end system.
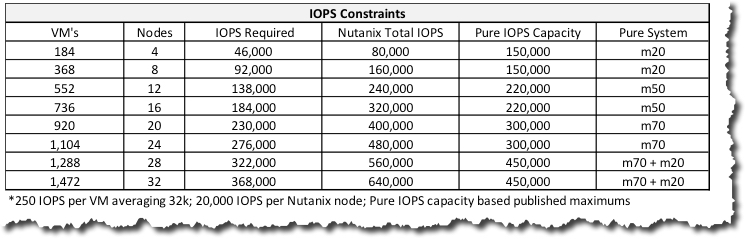
In our comparison we specified FlashArray//M20 systems, which Pure rates at 200,000 IOPS, from 4-20 nodes and the beefier //M50s, which Pure rates at 270,000 IOPS, for the larger clusters. Under Pure’s Evergreen Storage policy customers with active maintenance agreements can upgrade from the //M20 to the //M50 by paying just the difference in price between the two.
If we’re talking a node/compute server count of 32 as per the DeepStorage article (Pg9), then even with the “beefier” M50 model, we’re talking about a tad under 8.5K IOPS per server. Even at a relatively small 16 node/server cluster, the Pure solution as designed by DeepStorage is still only hitting around the 17K IOPS mark per server.
A single Nutanix NX-3460-G5 hybrid block (4 nodes), on the other hand, exceeds the performance of the higher end model (M50) on its own. DeepStorage concedes Nutanix scales more linearly which is a major advantage as performance remains at a consistent high level regardless of scale.
Most significantly, while Nutanix does scale more linearly…
I invite you to revisit my earlier point that the CVM improves CPU efficiency due to the excellent performance delivered to the virtual machines.
In 2013 I wrote, “Scaling problems with traditional shared storage”, which highlights the often overlooked issue when connecting more servers to a centralised SAN such as Pure Storage. As the environment supports more users, the controllers are infrequently at best increased/scaled which results in a lower IOPS per GB.
As more VMs and servers drive I/O to through the two controllers, the chance of contention such as noisy neighbour increases and this leads to increased latency and more CPU WAIT which drives down compute efficiency.
The counter argument to this, which I’m sure Pure Storage will make, is that its performance is so good that the impact is insignificant and the noisy neighbour problems can be mitigated with technology such as VMware Storage I/O Control. If we were to accept this premise, since one Nutanix block outperforms the M50 product, higher performance would mean Nutanix would have a clear advantage, especially at scale.
A quick note on Storage I/O Control and Nutanix, in short SIOC is not required or recommended as the Nutanix distributed / scale out architecture natively mitigates the noisy neighbour issues.
Scalability
DeepStorage.net makes a spurious claim, to say the least, about the two platforms’ scalability.
“The FlashArray’s wide range of expandability and Pure’s customer-friendly Evergreen Storage policies make the two systems roughly comparable in scalability.“
This statement is easily shown to be inaccurate by simply referring to Pure Storage’s own documentation which shows the raw capacity of their models.

As we see, the maximum raw capacity with expansion shelves is 136TBs for the M70 model. Now let’s review the Nutanix capacity according to the official website:

Here we can see the NX-3060-G5 can support up to 6 SSDs of up to 3.84TB each which equates to approx 23TB raw per node or 92TB raw per 4 node block.
To exceed the raw capacity of the larger Pure Storage M70 platform (136TB) requires just 6 NX-3060-G5 nodes with 6 x 3.84TB drives per node.
If we assume usable capacity of 136TB as opposed to RAW we need just 14 x NX-3060-G5 nodes (which fits in 8RU with room for two additional nodes).
Let’s take it a step further and assume Pure Storage’s claim of up to 400TB is realistic, Nutanix can achieve this WITHOUT data reduction with 40 x NX-3060-G5 nodes.
If we assume the 2:1 data reduction ratio DeepStorage.net suggests, just 20 nodes (fitting in just 10RU) are required as shown by the Nutanix disk usage calculator.

Nutanix can also scale capacity, performance and resiliency by using storage-only nodes. So from an outright capacity perspective, Nutanix can easily exceed what Pure Storage can provide but what about from a granularity perspective?
SANs are not the most scalable platforms, leading to risk and complexity in choosing the right controllers. Pure Storage has tried to mitigate these issues with the Evergreen storage policy which allows customers to upgrade to newer/faster controllers. This is, however, just a smart commercial play and does not solve the technical issues and limitations dual controller SANs have when it comes to scalability and resiliency.
Nutanix can start with 3 nodes and scale one node at a time, indefinitely. You never need to go to your Nutanix rep and ask for a controller upgrade, you just add to your existing investment as you need to with compute+storage, or storage only nodes.
Over say a 5 year period, with Pure Storage you might start small with an M20, then upgrade to an M50, add some shelves (which reduce performance from an IOPS/GB perspective) and finally upgrade again to an M70 when more performance or capacity is required.
Over the same 5 year period, Nutanix customers starting small with, say, 4 nodes, can continue to add nodes one at a time, as required, getting the benefit of the latest Intel CPUs, RAM , Flash and even network technology. They never need to migrate data, just add nodes to the cluster and performance instantly improves, capacity is instantly available and resiliency is improved as more nodes are available to contribute to a rebuild after a component failure. Older nodes that are, say, end-of-life, can also be non disruptively removed by vMotioning VMs off the nodes and marking the node for removal.
So in short, Nutanix can:
- Start Smaller (e.g.: 3 nodes in 2RU w/ as little as 2TB usable in 6 x 480GB SSD configuration)
- Scale in a more granular increment (configure to order node/s)
- Scale to support more raw/usable/effective capacity
- Scale more linearly (as DeepStorage.net conceded)
- Improve performance/capacity & resilience while scaling
- Scale storage only with the flexibility to mix all flash with hybrid.
- Benefit from newer CPU generations , Memory & Flash as you scale
And because the newer nodes are incorporating the latest technology advances (CPU, flash, etc.), the density of VMs per node continues to increase. As the Nutanix footprint expands along with the use case, project CAPEX is reduced along with associated rack space power and cooling. And, of course, Nutanix customers never face a disruptive upgrade of any kind.
The Nutanix 1-click non-disruptive upgrades play a part in reducing ongoing cost as well combined with frequent enhancements to Nutanix software which are deployed to existing nodes regardless of location or age with a single click. This means that even nodes which are years old have the latest and greatest capabilities (i.e. AFS, ABS, etc) along with running faster and having more storage capacity – in other words, supporting more VMs per node. This further reduces the number of newer nodes required which in turn further reduces the CAPEX for the project along with the associated rack space, power and cooling.
While the Pure Storage Evergreen story sounds nice on paper, there is no guarantee the platform will accommodate whatever technology changes are coming down the road. And even in the best case, Pure customers are stuck with older technology until they can implement the newer controllers. And the Evergreen policy is an additional cost.
Discounting
DeepStorage makes the claim:
“FlashStack delivers all flash performance at a cost below that of Nutanix Hybrid HCI”
The report fails to quantify this claim as no costs have been quoted for either platform. I opened this post stating that All Flash vs Hybrid is not apples to apples and is a significant difference. Interestingly, in my experience, street pricing for all flash NX-3060-G5 nodes is typically not much higher than hybrid, although market conditions around flash prices do vary especially in light of the current SSD shortage.
The DeepStorage statement also implies that Pure Storage delivers better performance which is also not quantified. As I discussed earlier, a single Nutanix block can deliver higher IOPS than the M20 and M50 models. So if we’re comparing a scale-out Nutanix cluster of, say, 32 nodes, we’re talking well into the multi-million IOPS range which vastly exceeds the advertised capabilities of Pure Storage.
In terms of cost to performance ratio, Nutanix (especially at scale) undoubtedly has the upper hand as performance scales linearly as the cluster grows.
But as DeepStorage has not specified workloads or requirements for this comparison, neither Pure Storage nor Nutanix can really quantify the performance levels. We’re stuck comparing hero numbers which are far from realistic.
A Word on Cisco UCS
DeepStorage covers many advantages of the Cisco UCS platform, and in large part I agree with what was said as far as UCS compared to traditional servers/storage.
When comparing Nutanix to UCS, which I should note is a supported platform for Nutanix, many of the advantages UCS provides are now all but redundant such as FCOE, Service Profiles and Stateless Computing. This is because the loss of a Nutanix node or block is automatically healed by the platform. There is no value in keeping a profile of a node when a new node can just be added back to the cluster in a matter of minutes. Nutanix nodes could be considered stateless in that the loss of a node (or nodes) does not result in lost data or functionality, and the node does not have to be recovered for the cluster to restore full resiliency.
Nutanix PRISM GUI provides one-click upgrades for Nutanix AOS, Hypervisors, Firmware, Acropolis File Services (AFS), Acropolis Container Services (ACS), Nutanix Cluster Check (NCC) and our built in node/cluster imaging tool Foundation. The value which Cisco UCS does undoubtedly provide for FlashStack, has long been built in as part of the Nutanix platform via the distributed and highly available HTML GUI, PRISM. (as shown below)

DeepStorage Report Conclusions (Couldn’t be further from the truth).
We have already covered the difficulty in directly comparing data reduction since the way it is measured can vary significantly between vendors. The DeepStorage report failed to provide evidence of either platform’s data reduction OR how each is measured making the following statement simply an assumption with no factual basis.
“When we adjusted our model to account for the greater data reduction capabilities of the Pure FlashArray…”
DeepStorage also provided no evidence that the CPU consumption of the Nutanix CVM has any negative impact on density as opposed to my aforementioned post which details the cost vs reward of the Nutanix CVM. We have also covered how a 4-node Nutanix block exceeds the performance of an M50 platform. Therefore, the claim that fewer servers are required for the FlashStack solution is again without basis.
“… and the CPU consumption by Nutanix’ storage CVM, the FlashStack solution was as much as 40% less expensive than the Nutanix.”
As for the claim that “FlashStack solution was as much as 40% less expensive,” we have shown that the calculations for power consumption made by DeepStorage were off by a factor of 4 making Nutanix the much cheaper solution from a power consumption, and therefore also cooling perspective.
DeepStorage conceded that “The Cisco C220s alone take up twice as much rack space, and the FlashArray will take up another 4-12U depending on the number of SSD shelves.” This is a very important, and often overlooked, factor when discussing cost – especially as commercial datacenter prices continue to increase.
Summary:
When 3rd parties write reports, they have a responsibility to make reasonable efforts to ensure the information is correct. After DeepStorage released its first report targeting Nutanix, I personally reached out prior to writing a response and voiced my concerns about the document’s accuracy.
I offered to review any material, at no charge, relating to Nutanix for accuracy. This offer has not been taken up by DeepStorage in either the original Atlantis report or in the two subsequent reports paid for by VMware and Pure Storage. In both of the later cases, and similar to the first report, there have been numerous significant factual/sizing errors in addition to sub-optimal architectural decisions in regard to the Nutanix platform.
It’s important to note that even after DeepStorage has been made aware of many issues with the three reports, not a single item has been revised (at the time of writing).