It never ceases to amaze me that analysts as well as prospective/existing customers frequently are not aware of the storage scalability capabilities of the Nutanix platform.
When I joined back in 2013, a common complaint was that Nutanix had to scale in fixed building blocks of NX-3050 nodes with compute and storage regardless of what the actual requirement was.
Not long after that, Nutanix introduced the NX-1000 and NX-6000 series which had lower and higher CPU/RAM and storage capacity options which gave more flexibility, but still there were some use cases where Nutanix still had significant gaps.
In October 2013 I wrote a post titled “Scaling problems with traditional shared storage” which covers why simply adding shelves of SSD/HDD to a dual controller storage array does not scale an environment linearly, can significantly impact performance and add complexity.
At .NEXT 2015, Nutanix announced the ability to Scale Storage separately to Compute which allowed customers to scale capacity by adding similar to a shelf of drives like they could with their legacy SAN/NAS, but with the added advantage of having a storage controller (the Nutanix CVM) to add additional data services, performance and resiliency.
Storage only nodes are supported with any Hypervisor but the good news in they run on Nutanix’ Acropolis Hypervisor (AHV) which means no additional hypervisor licensing if you run VMware ESXi, and storage only nodes still support all the 1-click rolling upgrades so they add no additional management overhead.
Advantages of Storage Only Nodes:
- Ability to scale capacity seperate to CPU/RAM like a traditional disk shelf on a storage array
- Ability to start small and scale capacity if/when required, i.e.: No oversizing day 1
- No hypervisor licensing or additional management when scaling capacity
- Increased data services/resiliency/performance thanks to the Nutanix Controller VM (CVM)
- Ability to increase capacity for hot and cold data (i.e.: All Flash and Hybrid/Storage heavy)
- True Storage only nodes & the way data is distributed to them is unique to Nutanix
Example use cases for Storage Only Nodes
Example 1: Increasing capacity requirement:
MS Exchange Administrator: I’ve been told by the CEO to increase our mailbox limits from 1GB to 2GB but we don’t have enough capacity.
Nutanix: Let’s start small and add storage only nodes as the Nutanix cluster (storage pool) reaches 80% utilisation.
Example 2: Increasing flash capacity:
MS SQL DBA: We’re growing our mission critical database and now we’re hitting SATA for some day to day operations, we need more flash!
Nutanix: Let’s add some all flash storage only nodes.
Example 3: Increasing resiliency
CEO/CIO: We need to be able to tolerate failures and the infrastructure self heal but we have a secure facility which is difficult and time consuming to get access too, what can we do?
Nutanix: Let’s add some storage only nodes to ensure you have enough capacity (All Flash and/or Hybrid) to ensure sufficient capacity to tolerate “n” number of failures and rebuild the environment back to a fully resilient and performant state.
Example 4: Implementing Backup / Long Term Retention
CEO/CIO: We need to be able to keep 7 years of data for regulatory requirements and we need to be able to access it within 1hr.
Nutanix: We can either add storage only nodes to one or more existing clusters OR create a dedicated Backup/Retention cluster. Let’s start with enough capacity for Year 1, and then as capacity is required, add more storage only nodes as the cost per GB drops over time. Nutanix allows mixing of hardware generations so you’ll never be in a situation where you need to rip & replace.
Example 5: Supporting one or more Monster VMs
Server Administrator: We have one or more VMs with storage capacity requirements of 100TB each, but the largest Nutanix node we have only supports 20TB. What do we do?
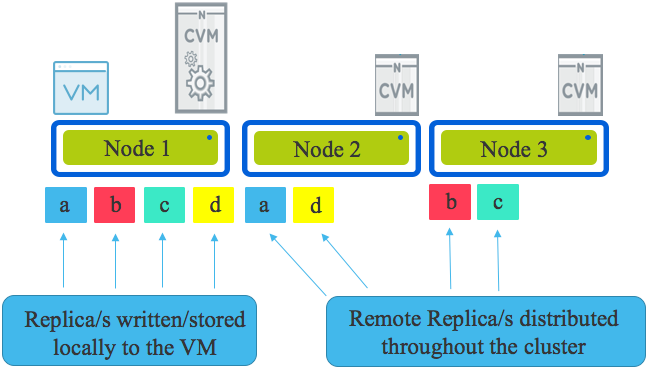
Nutanix: The Distributed Storage Fabric (ADSF) allows a VMs data set to be distributed throughout a Nutanix cluster ensuring any storage requirement can be met. Adding storage only nodes will ensure sufficient capacity while adding resiliency/performance to all other VMs in the cluster. Cold data will be distributed throughout the cluster while frequently accessed data will remain local where possible within the local storage capacity on the node where the VM runs.
For more information on this use case see: What if my VMs storage exceeds the capacity of a Nutanix node?
Example 6: Performance for infrequently accessed data (cold data).
Server Administrator: We have always stored our cold data on SATA drives attached to our SAN because we have a lot of data and flash is expensive. One or twice a year we need to do a bulk read of our data for auditing/accounting purposes but it’s always been so slow. How can we solve this problem and give good performance while keeping costs down?
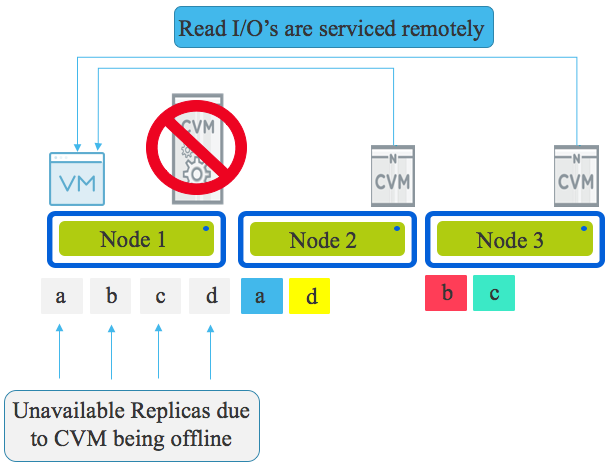
Nutanix: Hybrid Storage only nodes are a cost effective way to store cold data and combined with ADSF, Nutanix is able to deliver optimum read performance from SATA by reading from the replica (copy of data) with the lowest latency.
This means if a HDD or even a node is experiencing heavy load, ADSF will dynamically redirect Read I/O throughout the cluster to Deliver Increased Read Performance from SATA. This capability was released in 2015 and storage only nodes adding more spindles to a cluster is very complimentary to this capability.
Frequently asked questions (FAQ):
- How many storage only nodes can a single cluster support?
- There is no hard limit, typically cluster sizes are less than 64 nodes as it’s important to consider limiting the size of a single failure domain.
- How many Compute+Storage nodes are required to use Storage Only nodes?
- Two. This also allows N+1 failover for the nodes running VMs in the event a compute+storage node failed so VMs can be restarted. Technically, you can create a cluster with only storage only nodes.
- How does adding storage only node increase capacity for my monster VM?
- By distributing replicas of data throughout the cluster, thus freeing up local capacity for the running VM/s on the local node. Where a VMs storage requirement exceeds the local nodes capacity, storage only nodes add capacity and performance to the storage pool. Note: One VM even with only one monster vDisk can use the entire capacity of a Nutanix cluster without any special configuration.
Summary:
For many years Nutanix has supported and recommended the use of Storage only nodes to add capacity, performance and resiliency to Nutanix clusters.
Back to the Scalability, Resiliency and Performance Index.