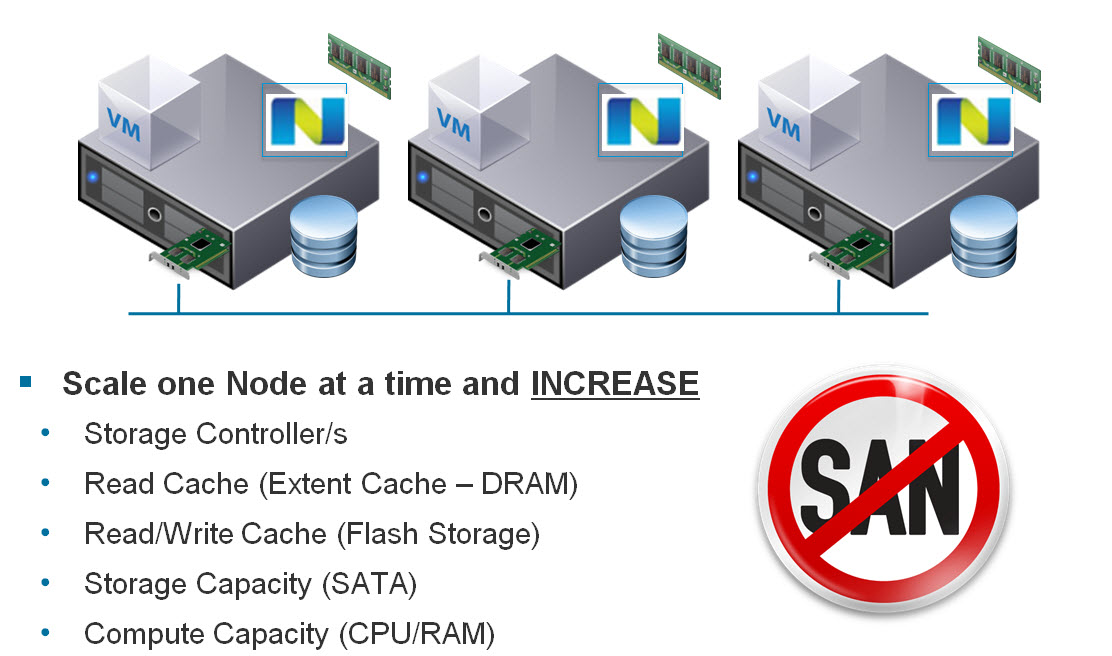
A quick bit of history on Nutanix, back in mid 2013 when I joined, in almost every meeting I went to, and presentation I gave, there was a common theme. People wanted to scale compute and storage at different rates.
Now this makes perfect sense, and this issue has long been addressed by a large range of node types which can be mixed in the same Nutanix cluster.
For example: NX3060 nodes with Dual Intel Haswell CPUs and ~2TB usable storage can be mixed with NX6060 nodes also running dual Intel Haswell CPUs but with ~8TB usable each.
Nutanix also has configure to order (CTO) nodes where size of SSDs and HDDs can be modified to suit customer requirements. So at this point I never have a challenge sizing for a customer workload as I have plenty of great options to choose from.
Another common question has been “How do I scale storage only?”. Nutanix has also addressed this in an intelligent way and as a result adding “Storage Only” nodes makes sense as I described in Scale Storage separately to Compute on Nutanix!
In recent months a new question has emerged and a small percentage of partners/customers have been asking about adding Compute only nodes (e.g.: Traditional ESXi hosts) to a Nutanix (or HCI) cluster.
My first question to these customers/partners is: Why?
The typical reply is something like “Because we need to add more VMs which have low storage requirements” or “Because we don’t need storage”.
Let’s look at these answers:
Firstly, my favourite one, “Because we don’t need storage”.
Is this really true, or do you mean the new VMs have low storage requirements. In almost all cases the truth is the new VMs have a small requirement for storage capacity and performance.
So next let’s look at the other common (and more realistic) situation:
“Because we need to add more VMs which have low storage requirements”
So this is very possible and something a HCI solution should cater for and for Nutanix we do. For example one of our most popular nodes is the NX-3050 or NX-3060 which are a compute heavy node with 2 sockets each with up to 24 physical CPU cores (Haswell) and 512GB RAM.
This node also comes with 2 x SSDs and 4 x SATA HDDs with a minimum usable capacity of approx 2TB (of which 20% is SSD).
So while the solution adds some capacity, its giving the added advantage of ensuring all the advantages of HCI while eliminating the complexity of a 3-tier architecture, which is why customers are flocking to HCI in the 1st place.
Even if the capacity is not required and the SSDs simply service the reads locally where required and increase the shared SSD tier of the cluster which means more write performance for workloads throughout the cluster. Sounds pretty good to me!
Does having an additional 4 x SATA drives really matter? Well from a cost perspective, its minimal cost and thanks to Disk Balancing, the SATA drives will hold some data (such as replicas) which lowers the overheads on other nodes, therefore improving resiliency and performance.
So there is lots of advantages to adding even a small amount of storage even if the new workloads don’t require most of it.
But for those of you who aren’t already convinced that adding some storage is advantageous, how about adding dual Intel Haswell CPUs and up to 512GB RAM just 1 x SSD to accelerate write I/O and serve what little storage locally that the VMs need and just 2 x SATA HDDs.
Nutanix has such a node, which is another option to scale high compute and very low storage.
Another question I get is: “Is the fact Nutanix can’t do this why you don’t recommend it?”
The answer is, Nutanix can add compute only, and we can actually do it very well and get very good performance, but its not HCI and it adds complexity which is not necessary which is why we don’t recommend (or Productise) this option.
Now let’s look at what adding compute only to HCI looks like?

*Scroll down when ready!
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V
V

Yuk! That looks like old school 3-tier stuff to me!
As the above shows, adding Compute Only to HCI basically means you have a non HCI solution for part of your workloads.
Non HCI workloads on compute only nodes would therefore:
- Be running in the same setup as traditional 3-tier infrastructure
- Have different performance than HCI based workloads
- Loose the advantage of having compute + storage close together
- Increase dependency on Network
- Impact network utilization of HCI node
- Impact benefits of HCI for the native HCI workloads and much more.
The industry has accepted HCI as they way of the future and while adding compute only nodes might sound nice at a high level, its just re-introducing the class 3-tier complexity and problems of the past.
Summary:
If you have already invested in HCI, you clearly understand the advantages and value of the solution. Adding compute only is not a true “value” its just a “perceived value”.
Adding “Compute only” is just adding complexity and moving away from the value HCI brings, so my advice, don’t make the mistake, but if you have, you now know the solution.
Invest in a compute+storage node (albeit at a higher CAPEX) and enjoy the continued value of HCI and improve performance and resiliency to your entire cluster! Now that’s real value (at a reasonable cost).
And just remember….

Related Posts:
1. Acropolis Hypervisor (AHV) I/O Failover & Load Balancing
2. Advanced Storage Performance Monitoring with Nutanix
3. Nutanix – Improving Resiliency of Large Clusters with Erasure Coding (EC-X)
4. Nutanix – Erasure Coding (EC-X) Deep Dive