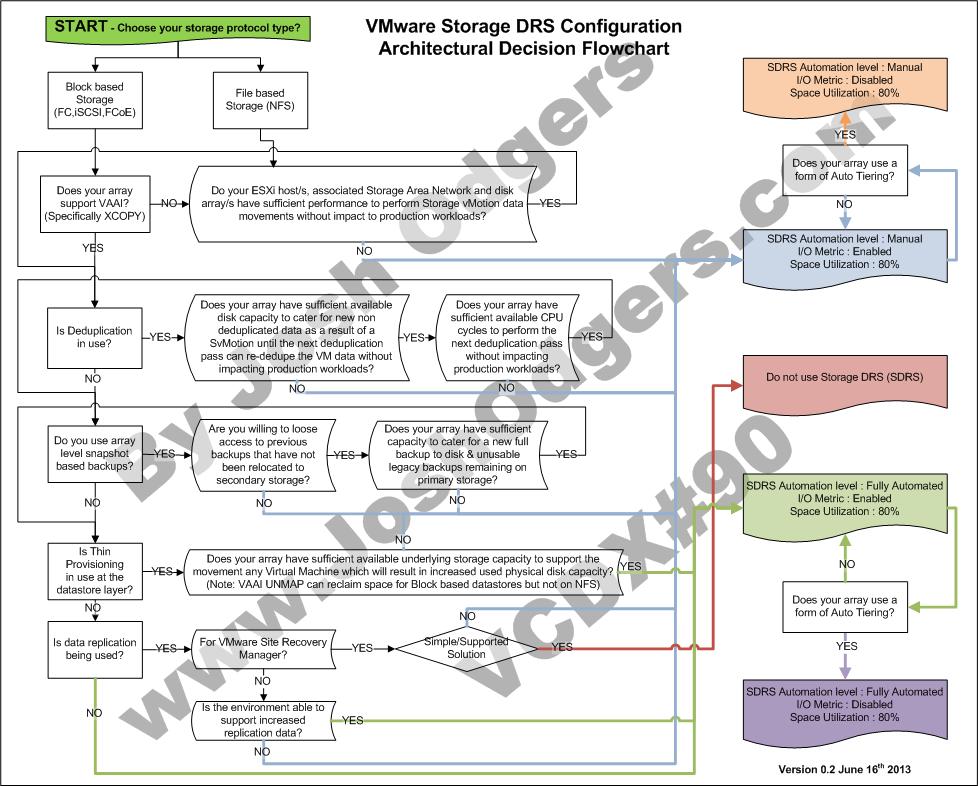
Storage DRS (SDRS) is an excellent feature which was released with vSphere 5.0 in late 2011. For those of you who are not familiar with SDRS I recommend reading the following article prior to reading the rest of this post as SDRS knowledge is assumed from now on.
Understanding VMware vSphere 5.1 Storage DRS
This post also assumes basic knowledge of the Nutanix platform, for those of you who are not familiar with Nutanix please review the following links prior to reading the remainder of this post.
About Nutanix | How Nutanix Works | 8 Strategies for a Modern Datacenter
Storage DRS & Nutanix – To use, or not to use, that is the question?
With Storage DRS (SDRS), both capacity and performance can be managed, but what should SDRS manage in a Nutanix environment?
Lets start with performance. SDRS can help ensure optimal performance of virtual machines by enabling the I/O metric for SDRS recommendations as shown in the screen shot below.

Once this is done, SDRS will evaluate I/O every 8 hours (by default) and where the configured latency threshold is exceeded, perform a cost/benefit analysis before deciding to make a migration recommendation or do nothing.
So the question is, does SDRS add value in a Nutanix environment from a performance perspective?
The Nutanix solution adopts the “Scale-out” methodology by having one (1) Nutanix Controller VM (CVM) per Nutanix Node (ESXi Host) and then presents NFS datastore/s to the vSphere cluster which are serviced by all CVMs. The CVMs use intelligent auto-tiering to ensure optimal performance. The way this works at a high level, is as follows.
Data is written to an SSD tier (either PCIe SSD such as Fusion-io or SATA SSD) before being migrated off to a SATA tier once the blocks are determined to be “Cold” and if/when required, promoted back the an SSD tier when they become “Hot” again for improved read performance.
As with other vendor storage solutions with auto tiering technologies (such as FAST-VP , FlashPools etc) the same recommendation around SDRS and the I/O metric is true for Nutanix, leave it disabled.
So, at this point we have concluded the I/O metric will be “Disabled”, lets move onto Capacity management.
The Nutanix solution presents large NFS datastore/s to the ESXi hosts (Nutanix nodes) which are shared across all ESXi hosts in one or more vSphere clusters.
When using SDRS, it can manage initial placement of a new Virtual machine based on the configured “Utilized Space” metric (shown below) to ensure there is not a capacity imbalance between the datastores in a datastore cluster, as well as move virtual machines around when new machines are provisioned to ensure the balance is maintained.
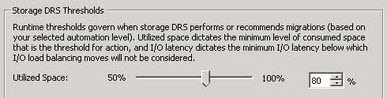
So this is a really good feature which I have and do recommend in several scenarios, however the Nutanix solution presents typical a small number of large NFS datastores to the vSphere cluster (or clusters) which are serviced by all Controller VMs (CVMs) in the Nutanix cluster. Using SDRS for initial placement does not add much (if any) value as the initial placement will almost always be on the same large NFS datastore.
Where actual physical capacity becomes an issue, space saving technologies such as compression can be enabled, or the environment can be granularly scaled by adding just a single additional Nutanix node which linearly scales the solution from both a capacity and performance perspective.
The only real choice is when you choose to present two (or more) datastores where one datastore leverage’s the Nutanix compression technology. This is a very easy scenario for a vSphere admin to choose the placement of a VM and is the same amount of administrative effort as choosing a datastore cluster which would be a collection of datastores either using compression, or not depending on the workloads.
As a result there is no advantage to using SDRS to manage utilized space.
In conclusion, Storage DRS is a great feature when used with storage arrays where performance does not scale linearly or provide intelligent tiering to address I/O bottlenecks and/or where your environment has large numbers of datastores where you need to actively manage capacity.
As performance and capacity management are intelligently managed natively by the Nutanix solution, the requirement (or benefit) provided by SDRS is negated, as a result there is no requirement or benefit for using SDRS with a Nutanix solution.
Related Articles
1. Example Architectural Decision – VMware DRS automation level for a Nutanix environment