*UPDATE March 30th 6am EST*
Following an email from Howard Marks, the author of the Atlantis document, I would like to confirm a few points, but overall the feedback and this response from Howard, simply confirmed my original comments found in this post but it also raised new concerns.
- It has been confirmed that the 60,000k Exchange user solution could not be supported on the hardware as described in the Atlantis document.
- The performance (IOPS) claims are based on a non DAG configuration. This then is clearly not a real world solution as nobody would deploy a 60,000 user Exchange solution without a DAG configuration.
- The testing was purely storage based and did not take into account the requirements (such as CPU/RAM/Capacity) for a real world 60,000 user Exchange deployment.
- The Nutanix ESRP is not based on hero numbers. Its a solution sized and tested for a real world solution, thus the original claim and the latest claim from Howard’s response being “Hero numbers vs Hero Numbers” and the original claim of “2.5 times the mailboxes and 5 times the IOPS” are both incorrect.
- Nutanix ESRPs are 1GB and 1.5GB respectively. The Atlantis product tested “would be stressed to hold the data for 60,000 mailboxes at 800MB each. Perhaps we should have set the mailbox size to 200MB”. This confirms the comparison is not Apples/Apples (or even tangerines and clementines).
- The industry standard for Exchange virtualization is to deploy no more than one DAG instance per host (or HCI node). Howard responded by stating “If I were trying to deploy Exchange on a four-node HCI appliance, as opposed to Jetstress, I would use twelve virtual Exchange servers, so each host would run three under normal conditions and four in the event of a node failure.” – This would mean if a DAG configuration was used (which it should be for any real world deployment, especially at this scale) then a single node failure would bring down three Exchange instances, and as a result, the entire DAG. This is Exchange virtualization 101 and I would never recommend multiple Exchange servers (within a DAG) per host/node. I describe this in more detail in How to successfully Virtualize MS Exchange – Part 4 – DRS where I explain”Setup a DRS “Virtual Machines to Hosts” rule with the policy “Should run of hosts in group” on a 1:1 basis with Exchange MSR or MBX VMs & ESXi hosts” and summarized by saying the DRS configuration described “Ensures two or more DAG members will not be impacted in the event of a single ESXi host failure.
- Howard mentions “My best understanding of Nutanix’s and Atlantis’ pricing is that the all-flash Atlantis and the hybrid Nutanix will cost a customer about the same amount of cash. The Nutanix system may offer a few more TB of capacity but not a significant amount after Atlantis’ data reduction.” In the original document he states “Atlantis is assuming a very conservative data reduction factor of 1.67:1 when they pitch the CX-12 as having 12TB of effective capacity.”. This is 12TB across 4 nodes, which equates to 3TB per node. The Nutanix NX-8150 can support ~16.50TB usable per node with RF2 without data reduction which is above the CX-12 capacity including data reduction. The Nutanix usable capacity is obviously a lot more with In-Line compression and EC-X enabled which is what we recommend for Exchange. Assuming the same compression ratio, the NX-8150 usable capacity jumps to 27.5TB with further savings available when enabling EC-X. This usable capacity even eclipses the larger Atlantis CX-24 product. As such, the claim (above) by Howard is also incorrect.
My final thoughts on this topic would be that Atlantis should take down the document, as it is misleading to customers and only provides Jetstress performance details without the context of the CPU/RAM requirements.The testing performed was essentially just an IOPS drag race, which as I quoted in “Peak Performance vs Real World Performance“…
“Don’t perform Absurd Testing”. (Quote Vaughn Steward and Chad Sakac)
As a result the document has nothing which could realistically be used to help design an Exchange environment for a customer on Atlantis,
As such it would make sense to redo the testing to a standard where it could be deployed in the real world, update the document and republish.
Remember: Real world Exchange solutions are typically constrained by RAM, then CPU, then Capacity. As a result it all but negates the need for IOPS (per node) beyond that which was achieved in the Nutanix ESRP report being 671.631. This level of IOPS would support 5535 users per node using Howard’s calculation being “(for 150 messages/day, that’s 0.101) multiply by 1.2 to provide 20% headroom”. However as Exchange is constrained by CPU/RAM first, the solution would have to scale out and use many more servers, meaning the IOPS requirement per node (which is what matters as opposed to “total iops” which is what Howard provides), would be in the mid/high hundreds range (~600), not thousands as the RAM constraint would prevent more users running per server and therefore as I said earlier, negate the need for IOPS at the level Howard is talking.
—— START OF ORIGINAL POST ——-
So Nutanix has been called out by Atlantis on Twitter and via an Atlantis document recently released regarding our MS Exchange ESRP. Atlantis, a little known company who are not listed in the Gartner Magic Quadrant for Integrated Systems, or the IDC marketscape for HCI, attempted to attack Nutanix regarding our Exchange ESRP (or should I say multiple ESRPs) in what I found to be a highly amusing way.
I was reading the document published by Atlantis which is titled “Atlantis HyperScale Supports 60,000 Mailboxes With Microsoft Jetstress” and I honestly thought it was an April Fools joke, but being that its only March 25 (at least here in Australia), I concluded they must be serious.
I’ve got to be honest and say I don’t see Atlantis in the field, but one can only speculate they called Nutanix out to try and get some attention. Well, they have succeeded, I’m just not sure this exposure will be beneficial to them.
Lets look at the summary for their document:

- Deduping Exchange DAGs
This is widely not recommended by Microsoft and Exchange MVPs.
- (Update) Claiming support for 60k mailboxes at
200 150 message/day/mailbox
No issue here, large-ish environment and reasonably high messages/per/day.
- 2.5x the mailboxes of a leading HCI providers ESRP (i.e.: Nutanix)
Had a good chuckle here as ESRP is not a competition to see what vendor has the most hardware lying around the office to perform benchmarks. But I appreciate that Atlantis want to be associated with Nutanix so go you ankle biter you!
- Five times the IOPS of Nutanix
This was even more of a laugh as Nutanix has never published “peak” IOPS for Exchange as IOPS is almost never a limiting factor in the real world as I have explained in Peak performance vs Real World – Exchange on Nutanix Acropolis Hypervisor (AHV) but hey, the claim even though its not true makes for a good marketing.
Problem #1 – Atlantis document is not an ESRP, it’s a (paid for?) analysts report.
The article claims:
“2.5 times the mailboxes of a leading HCI provider’s ESRP report”
Off the bat, this is an Apples/Oranges comparison as Atlantis doesn’t have an ESRP validated solution. This can be validated here: Exchange Solution Reviewed Program (ESRP) – Storage
More importantly the number of mailboxes is irrelevant as Nutanix scales linearly, so our ESRP validates 30,000 users, simply double the number of nodes, scale out the DAG and you can support 60,000 users with the same performance. In fact, as the 30,000 user solution already has N+1, you don’t even need to double the number of nodes to get 60,000 users.
Nutanix ESRP is also a configuration which can (and has been) deployed in the real world. As I will explain further in this post, the Atlantis solution as described in the document could not be successfully deployed in the real world.
Problem #2 – Five times more IOPS… lol!
The article claims:
“Five times the IOPS of that HCI provider’s system”
Another apples/oranges comparison as Nutanix uses a hybrid deployment (SSD + SATA) whereas Atlantis used an All-Flash configuration. Atlantis also used deduplication and compression, which I have previously blogged about in Jetstress Testing with Intelligent Tiered Storage Platforms where I conclude by saying:
No matter what any vendor tells you, 8:1 dedupe for Exchange (excluding DAG copies) is not realistic for production data in my experience. As such, it should never be used for performance testing with Jetstress.
Solution: Disable dedupe when using Jetstress (and in my opinion for production DAGs)
So any result (including this one from Atlantis) achieved with Dedupe or Compression enabled is not realistic regardless of if its more/less IOPS than Nutanix.
But regarding Nutanix All-Flash performance, I have previously posted YouTube videos showing Nutanix performance which can be found here: Microsoft Exchange 2013/2016 Jetstress Performance Testing on Nutanix Acropolis Hypervisor (AHV)
In Part 1 of the series “The Baseline Test” I explained:
Note: This demonstration is not showing the peak performance which can be achieved by Jetstress on Nutanix. In fact it’s running on a ~3 year old NX-3450 with Ivy Bridge processors and Jetstress is tuned (as the video shows) to a low thread count.
So lets look at Nutanix performance on some 3yo old hardware as a comparison.
At the 4:47 mark of the video in Part 1 we can see the Jetstress latency for Read and Write I/O was between 1.3 and 1.4ms for all 4 databases. This is considerably lower and critically much more consistent than the latency Atlantis achieved (below) which varies significantly across databases.

As you can see above, DB read latency varies between 3ms and 16ms, DB writes between 14ms an 105ms and Log Writes between 2ms and 5ms. In 2013 when I joined Nutanix, we had similar (poor) performance for Exchange that the Atlantis Jetstress results show, and this was something I was actively involved with addressing, and by early 2014 we had a fantastic platform for Exchange deployments as we did a lot of work in the back end to deal with very large working sets which exceeded SSD tier.
In contrast, Nutanix NX-8150, which is a hybrid (SSD + SATA) node, achieved very consistent performance as shown below from our official ESRP which has been validated by Microsoft.

Obviously being Nutanix is hybrid, the average latency for reads which the bulk of are served from SATA are higher than an all flash configuration, but interestingly, Nutanix latencies are much more consistent and the difference between peak and minimal latency is low, compared to Atlantis which varies in some cases by 90ms!
In the real world, I recently visited a large customer who runs almost the exact same configuration as our ESRP and they average <5ms latency across their 3 Nutanix clusters running MS Exchange for 24k users (Multi-site DAG w/ 3 Copies).
At the 4:59 mark of the Baseline Test video we can see the Nutanix test achieved 2342 IOPS using just 8 threads, compare this to Atlantis, where they achieved 2937.191 IOPS but required 3x the threads (24). For those of you not familiar with Jetstress, more threads = more potential IOPS. I have personally tested Nutanix with 64 threads and performance continues to increase.
Using more threads I have previously blogged about how Nutanix outperformed VSAN for Jetstress which showed the following Jetstress summary showing 4381 IOPS using more threads. So actually, Nutanix comfortably outperforms Atlantis even back in June 2015 when I wrote that post. With the release of AOS 4.6 performance has improved significantly.

So Nutanix Exchange performance isn’t limited by IOPS as I explained in Peak performance vs Real World – Exchange on Nutanix Acropolis Hypervisor (AHV).
Exchange scale/performance is always constrained by RAM first (96GB), then CPU (20vCPUs) and typically in HCI environments, Storage Capacity, and a distant fourth, potentially being IOPS.
Problem #3 The solution could not be deployed in the real world
Tony Redmond a well known Microsoft Exchange MVP has previously blogged about unrealistic ESRP submissions such as: Deficient IBM and Hitachi 120,000 mailbox configurations
Tony rightly points out:
“The core problem in IBM’s configuration is that the servers are deficient in memory”
The same is true for the Atlantis document, With just 3 servers, that’s 20,000 users per server. In the configuration they published, that would mean the mailbox servers would vastly exceed the recommended sizing for an Exchange instance of 20vCPUs and 96GB RAM.
The servers Atlantis are using have Intel E5-2680 v3 processors which have a Spec base rate of between ~57 and 61 depending on the exact server vendor, so lets use the higher number to give Atlantis the benefit of the doubt: So Intel E5-2680 v3 processors have 12 cores, in a 2 socket host thats 24 x 61 = A maximum SpecIntRate of 1464.
Again to give Atlantis the benefit of the doubt, lets assume their VSA uses zero resources and see if we have enough compute available for the 20,000 users they tested in the real world.
The first issue is the Exchange 2013 Server Role Requirements Calculator reports the following error:

I solved this by adding a fourth server to the sizing since I’m a nice guy.
The second issue is the Exchange 2013 Server Role Requirements Calculator reports the following error (even with the fourth server being added).

Ok, not the end of the world I guess, Oh wait… then comes the third issue:

Each of the four mailbox servers vastly exceed the recommended maximums for Exchange 2013 servers (physical or virtual) being 20vCPUs and 96GB RAM.
Reference: Exchange 2013 Sizing and Configuration Recommendations
The below is a screenshot from the above link highlighting the recommendation from MS as at the time/date this article was published. (Friday 25th 2015 AEST)

In fact, they exceed the resources of the tested equipment as well. The testing was performed on Atlantis HyperScale CX-12 systems which have only 256GB RAM each 384GB each.
The below is from page 6 of the Atlantis document:
We performed our testing remotely on a HyperScale CX-12 system, with 256GB of RAM per node, in Atlantis’ quality-control lab.
Update: The solution has 384Gb RAM, which is still insufficient for the number of users and messages per day in the real world.
In this case, Atlantis, even with the benefit of the doubt of a fourth server and maximum SpecIntRate, would be running 332% utilisation on CPU even when using over 3 times the recommended maximum number of pCores and requiring almost 1TB of RAM per Exchange Server. That’s almost 10x the recommended RAM per instance!
So as if the first three weren’t enough, the fourth issue is kind of funny.
The required capacity for the solution (60k users @ 800MB Mailboxes w/ 2 DAG copies) is shown below. If you look at the Database Volume Space Required line item, it shows ~46TB required capacity per server not including restore volume.

Let’s keep giving Atlantis the benefit of the doubt and accept their claim (below) relating to data reduction.
Atlantis is assuming a very conservative data reduction factor of 1.67:1
So that’s 46TB / 1.67 = ~27.54TB required usable capacity per Exchange server. So that’s ~110TB for the 4 Exchange servers.
The HyperScale CX-24 system is guaranteed to provide up to 24TB according to the document on Page 6, screenshot below.

With a requirement for 27.54TB per node (and that’s with 4 servers, not 3 as per the document), the solution tested has insufficient capacity for the solution even when giving Atlantis the benefit of the doubt regarding its data reduction capabilities.
Prior to publishing this blog, I re-read the document several times and it turns out I made a mistake. On further analysis I discovered that the Hyperscale CX-24 system provides just 24TB across ALL FOUR NODES, not one node as per the document on Page 8.

So in reality, my above comments were actually in favour of Atlantis, as the actual nodes have (24/4) just 6TB usable each, which is just under 5x LESS storage capacity than is required assuming 100% capacity utilisation.
The fifth issue however takes the cake!
The solution requires 4824 IOPS for the Databases and 1029 IOPS for Logs as shown by the sizing calculator.

Now the Atlantis document shows they achieved 2937.191 IOPS on Page 10, so they are not achieving the required IOPS for the 60000 users even with their all Flash configuration and 24 threads!
I would have thought a storage company would at least get the storage (capacity and IOPS) sizing correct, but both capacity and IOPS have not been sized for correctly.
Too harsh?
Ok, maybe i’m going a little honeybadger on Atlantis, so lets assume they meant 150 messages/day per mailbox as the document says both 200 messages (Page 4) and then the following on Page 11.

If I change the messages per day to 150 then the IOPS requirement drops to 3618 for DBs and 773 for Logs as shown below.

So… they still failed sizing 101, as they only achieved 2937 IOPS as per Page 10 of their document.
What about CPU/RAM? That’s probably fine now right? Wrong. Even with the lower messages per day, each of the 4 Exchange instances are still way over utilized on CPU and 8x oversized on RAM.

Let’s drop to 50 messages per day per user. Surely that would work right? Nope, we’re still 3x higher on RAM and over the recommended 80% CPU utilisation maximum for Exchange.

What about IOPS? We’ve dropped the user profile by 4x. Surely Atlantis can support the IOPS now?
Woohoo! By dropping the messages per day by 4x Atlantis can now support the required IOPS. (You’re welcome Atlantis!)

Too bad I had to include 33% more servers to even get them to this point where the Mailbox servers are still oversized.
Problem #4 – Is it a supported configuration?
No details are provided about the Hypervisor storage protocol used for the tests, but Atlantis is known to use NFS for vSphere, so if VMDK on NFS is used, this configuration is not supported by MS (as much as I think VMDK on NFS should be). Nutanix has two ESRP validated solutions which are fully supported configurations using iSCSI.
UPDATE: I have been informed the testing was done using iSCSI Datastores (not In-Guest iSCSI)
However, this only confirms this is not a supported configuration (at least not by VMware) as Atlantis are not certified for iSCSI according to the VMware HCL as of 5 mins ago when I checked (see below which shows only NFS).

Problem #5 – Atlantis claims this is a real world configuration

The only positive that comes out of this is that Atlantis follow Nutanix recommendations and have an N+1 node to support failover of the Exchange VM in the event of a node failure.
As I have stated above, unfortunately Atlantis have insufficient CPU,RAM,storage capacity and storage performance for the 60000 user environment described in their document.
As the testing was actually on Hyperscale CX-12 nodes the usable capacity is 12TB for the four node solution. The issue is we need ~110TB in total for the 4 Exchange servers (~27TB per instance), so with only 4 nodes it means Atlantis has insufficient capacity for the solution (actual guaranteed usable is 12TB or almost 10x less than what is required) OR they are are assuming >10x data reduction.
If this is what Atlantis recommends in the real world, then I have serious concerns for any of their customers who try to deploy Exchange as they are in for a horrible experience.
Nutanix ESRP assumes ZERO data reduction, as we want to show customers what they can expect in the worst case scenario AND not cheat ESRP by deduping and compressing data which results in unrealistic data reduction and increased performance.
Nutanix compression and Erasure Coding provide excellent data reduction, in a customer environment I reviewed recently which is 24k users, they had >2:1 data reduction using just In-Line compression. As they are not capacity constrained EC-X is currently not in use but this would also provide further savings and is planned to be enabled as they continue putting more workloads into the Nutanix environment.
However Nutanix size assuming no data reduction and the savings from data reduction are considered a bonus. In cases where customers have limited budget I give customers estimates on data reduction. But typically we just start small, size for smaller mailbox capacities and allow the customer to scale capacity as required with additional storage only nodes OR additional compute+storage nodes where additional messages/day or users are required.
Rule of Thumb: Use data reduction savings as a bonus and not for sizing purposes. (Under promise, over deliver!)
Problem #6 – All Flash (or should I say, All Tier 0/1) for Exchange?
To be honest, I think a hybrid (or tiered) storage solution (HCI or otherwise) is the way to go as its only a small percentage of workloads which require the fastest performance. Lots of applications like Exchange require high capacity and low IOPS, so lower cost, high capacity storage is better suited for this kind of workload. Using a small persistent write/read buffer for hot data gives the Tier 0/1 type performance without the cost, all while having much larger capacity for larger mailboxes/archiving and things like LAGGED copies or snapshot retention on primary storage for fast recovery (but not backup of course since snapshots on primary storage are not backups).
As SSD prices come down and technology evolves, I’m sure we’ll see more all SSD solutions, but with faster technology such as NVMe as the persistent read/write buffers and commodity SSD for capacity tier. But having the bulk of the data from workloads like Exchange on Tier 0/1 doesn’t make sense to me. The argument that data reduction makes the $/GB comparable to lower tier storage will fluctuate over time while the fact remains, storage IOPS are of the least concern when sizing for Exchange.
Problem #7 – $1.50 per mailbox… think again.
The claim of $1.50 per mailbox us just simply wrong. With correct sizing, the Atlantis solution will require significantly more nodes and the price will be way higher. I’d do the math exactly, but its so far fetched its not worth the time.
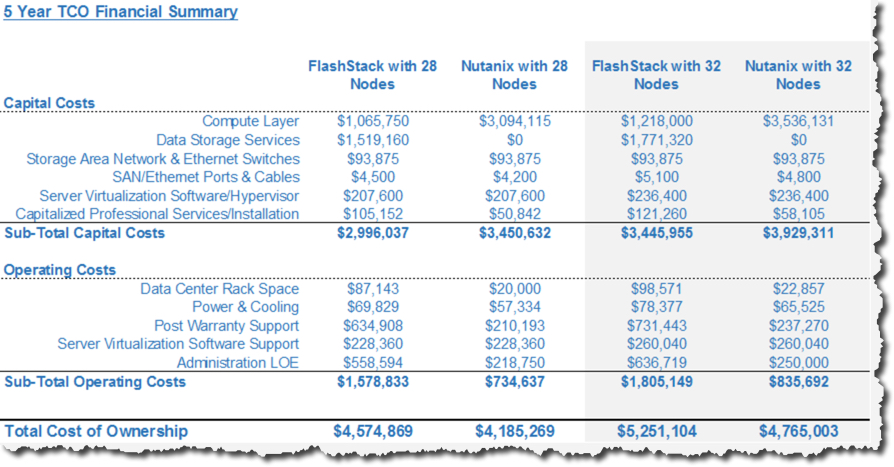
Summary:
I would be surprised if anyone gets to this summary, as even after Problem #1 or #2 Atlantis have been knocked out faster than Jose Aldo at UFC194 (13 seconds). But none the less, here are a few key points.
- Atlantis solution has insufficient CPU for the 60000 users even with 4x less messages per day than the document claims
- Atlantis solution has insufficient RAM for the solution, again even with 4x less messages per day than the document claims
- Atlantis can only achieve the required IOPS by reducing the messages per day by 4x down to 50 messages per day (funnily enough that’s lower than the Nutanix ESRP)
- The nodes tested do not have sufficient storage capacity for the proposed 60,000 users w/ 800MB mailboxes and 2 DAG copies even with the assumption of 1.67:1 data reduction AND a fourth node.
- Atlantis does not have a supported configuration on VMware vSphere (Nutanix does using “Volume Groups” over iSCSI)
- Atlantis does not have an ESRP validated solution. I believe this would be at least in part due to their only supporting NFS and their configuration not being valid for ESRP submission due to having all DAG copies on the same underlying storage failure domain. Note: Nutanix supports iSCSI which is fully supported and our ESRP uses two failure domains (seperate Nutanix ADSF clusters for each DAG copy).
- As for the $/Mailbox claim on twitter of $1.50 per mailbox, think again Atlantis.


{kind=link}