I find it difficult to understand how any Account Manager, Sales Engineer or Consultant can go to a customer, who is at least in part trusting their statements & opinions when considering new product/s and make claims that a product is performing a “backup” function when the data remains on the same primary storage system (failure domain).
Most vendors have metadata or snapshot based options which allow space efficient recovery points to be maintained on primary storage for fast recovery and any vendor worth talking to will also tell you that until a FULL COPY of the data is maintained off the primary storage, it is NOT a backup.
Some vendors will play games and try and differentiate and say they don’t use snapshots and they are somehow amazing and unique. In reality, they can say whatever they like, but if the end result is the data is only maintained on primary storage, then its not a backup and you should not treat it like one.
In the old days, it was fairly common to have Primary data on one set of LUNs/RAID packs and for customers to keep full copies of data on different LUNs and underlying RAID packs before offloading to tape.
While the copy of data remained on primary storage, it at least meant that in the event the RAID pack/s hosting the primary data failed (e.g.: Double disk failure in a RAID 5) then data could be recovered and if not, then the customer could restore form tape.
As storage became more intelligent, keeping the full copy became less popular in favour of snapshot or metadata based copies. This makes a lot of sense as it reduced the overheads significantly while achieving a business outcome which allows for fast recovery in the event the Primary Storage is not impacted.
However, the requirement for data to be kept off the primary storage remains, as no matter what vendor you choose, its possible to have a catastrophic failure which means the snapshot/metadata copies on primary storage may not be available.
Also promoting that snapshots (or any form of metadata copies pointing to the same underlying blocks) are this amazing new data reduction technology which achieves 60:1 or 100:1 data reduction is misleading at best in my opinion.
So let’s cover off a few things:
Question 1: Are snapshots or metadata copies of data stored on primary storage a backup?
Answer: No
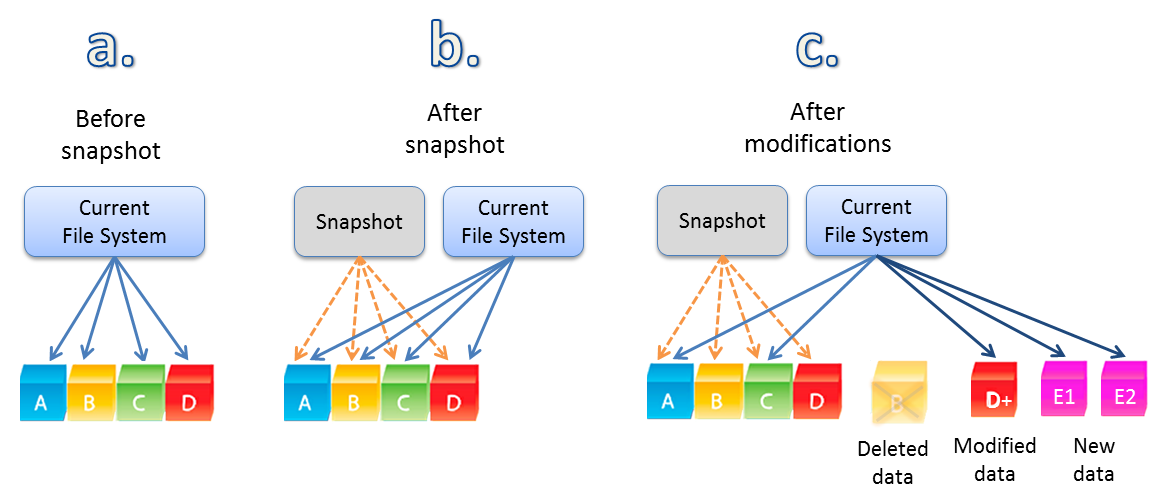
A snapshot or metadata based copies simply makes some data at various levels such as a vDisk, Virtual Machine , LUN , Container etc read only and new writes (commonly referred to as delta changes) are written elsewhere.
The data still resides on the same storage, meaning if data loss occurs (say multiple drive failures or storage system software issue) its possible if not probable that the data being referenced by the snapshot/metadata and delta changes will all be lost (or at least unavailable) in some failure scenarios depending on the vendor.
So having snapshot or metadata based copies on primary storage as a backup without at least one full copy in a seperate failure domain is simply asking for trouble.
Snapshots/metadata copies are only the first step in a backup solution which must ensure data is stored in at least two locations (different failure domains) so that data can be recovered in the event the primary storage is lost/unavailable for any reason.
Question 2: Are snapshots data reduction?
Answer: No
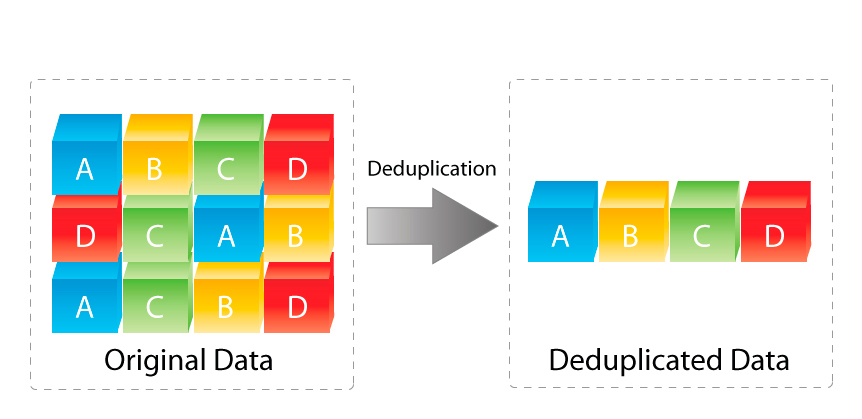
Snapshots and metadata copies don’t reduce data, they simply avoid creating and requiring the storage to store more data than is necessary to keep the point in time (or Recovery Point) copies (not backups) of data.
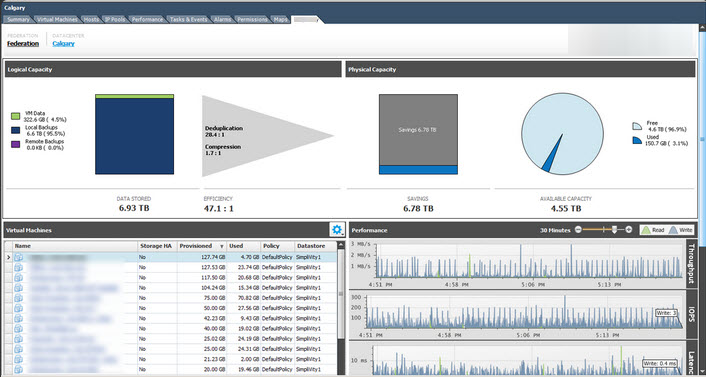
This is Data avoidance, not data reduction which cover this topic in more depth in a previous post: Deduplication ratios – What should be included in the reported ratio?
Now don’t get me wrong, Data avoidance (e.g.: Snapshots, Intelligent Cloning etc) has real value and its something I would recommend customers leverage wherever possible as it generally reduces the overheads on infrastructure significantly which can help achieve business outcomes like more frequent RPOs or faster deployment/maintenance times for VDI.
However making a claim that a customer has 60:1 or 100:1 data efficiency because they are taking frequent snapshots/metadata copies (which in many cases are unnecessary to meet business objectives) in my opinion is misleading customers and worse still, claiming its unique (as in other vendors cant achieve the same business outcome) is just a flat out lie.
Now I work for Nutanix, so let’s use another Vendor as an example, and one which I have lots of experience with from my years at IBM. Take Netapp (a.k.a IBM N-Series), for many years they have supported taking snapshots which are application consistent (via SnapManager) and keeping them on Primary storage. They as with many other vendors (new and legacy) do it in a way which avoids storing multiple copies of data and they redirect on write all delta changes which can be snapped at the next scheduled interval.
This results in the ability to keep lots of point in time copies without storing data multiple times. You could argue this is a ratio of “Insert crazy number here” :1 but the reality is, if the storage you have wasn’t storing 1:1 copies previously (which only a select few legacy products still do), a new solution doing similar isn’t a big step forward even if it could be argued it’s a bit more efficient.
Netapp allows these snapshots on primary storage to then be replicated to secondary storage (SnapVault) which is a different failure domain, with dedicated controller/s and disks. This allows for recovery of all data in the event the primary storage fails or is unavailable. Netapp also allow offload of snapshots to tape.
Many other vendors have similar functionality (and have for a long time) include but are not limited too: Pure Storage, Nutanix, EMC , Dell , IBM, the list goes on.
This functionality is table stakes… Not something unique to any one vendor or something that requires proprietary hardware to achieve.
Any vendor listed above (and others) can achieve the similar levels of data efficiency (if you want to use that term) if they all perform snapshots or metadata based copies at the same frequency. Each vendors implementations vary and each have pros and cons, but from a business outcome perspective (which is the ONLY thing that matters), its table stakes.
Question 3: What are Snapshots/Metadata copies on Primary storage good for?
Answer: They are good for creating recovery points to help achieve Recovery Point Objectives (RPOs) when combined with replication to secondary storage and/or tape/cloud to cater for site loss scenarios. Keeping snapshots on primary storage helps speed up recovery in the event you need to role back to a previous point in time assuming you have not had a storage failure. e.g.: Recovering a file or DB which was accidentally deleted or was corrupted for whatever reason.
So there is value in snapshots/metadata copies on primary storage, but it should not be considered a backup until it is replicated to another location, ideally offsite in a difference failure domain.
Summary:
Snapshots/Metadata based copies (on primary storage) are just the first step of many in an overall backup strategy. If the data is not replicated to another failure domain, it should not be called or considered a backup.
Marketing Claims of 60:1 or 100:1 data efficiency may sound good, but these sorts of numbers have been and can be achieved by many vendors for a long time. Be very careful when considering new infrastructure not to be mislead by these sorts of marketing claims.
Most vendors don’t market numbers like 60:1 or 100:1 because they understand its table-stakes and misleading for customers, and kudos to those vendors!
Snapshots/Metadata copies regardless of data efficiency ratio are USELESS in the event of a primary storage failure unless a full copy of the data is stored off the primary storage and depending on the business requirements, stored offsite.
I encourage the everyone, especially the industry analysts to help clarify this situation for customers as there is A LOT of mis-information being spread currently which puts customers at risk in the event of primary storage failures.