
It seems of late there is more and more people claiming to be VCDX as well as VCAP when they are not. This to me shows the people have no integrity and I would not want to work with a person who lied about a certification to try and get a job.
Luckily there is an easy way to validate if a person has a certification or not.
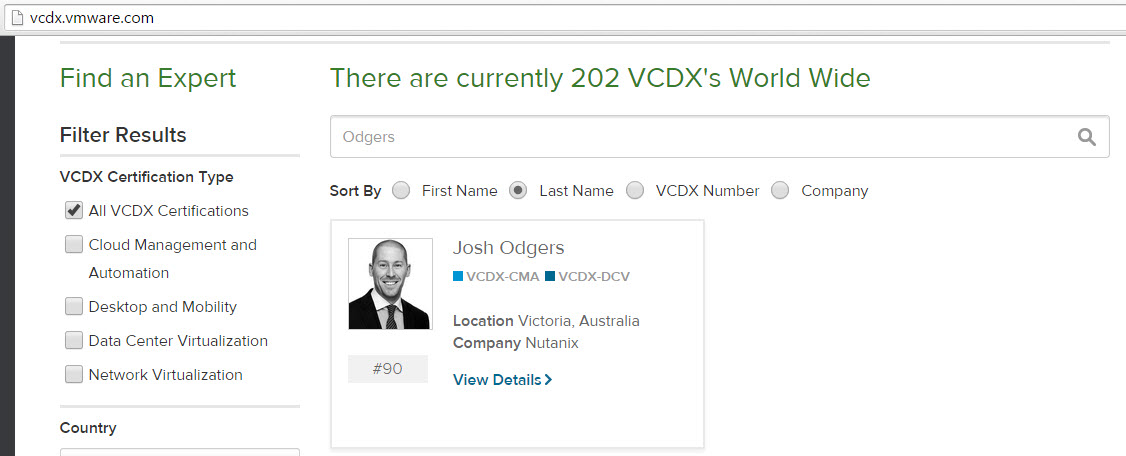
For VCDX its super easy, visit http://vcdx.vmware.com and enter the persons First Name, Last Name , VCDX Number or Company and you can quickly find out if they are VCDX or not.
See example below:
Another way is to have the person login to http://mylearn.vmware.com and open their transcript. The transcript shows all VMware certifications including VCA , VCP, VCAP , VCIX and VCDX.
The following shows part of my transcript which shows VCDX, VCAP and VCP certs inc:
- VMware Certified Design Expert – Cloud
- VMware Certified Advanced Professional – Cloud Infrastructure Administration
- VMware Certified Professional – Cloud
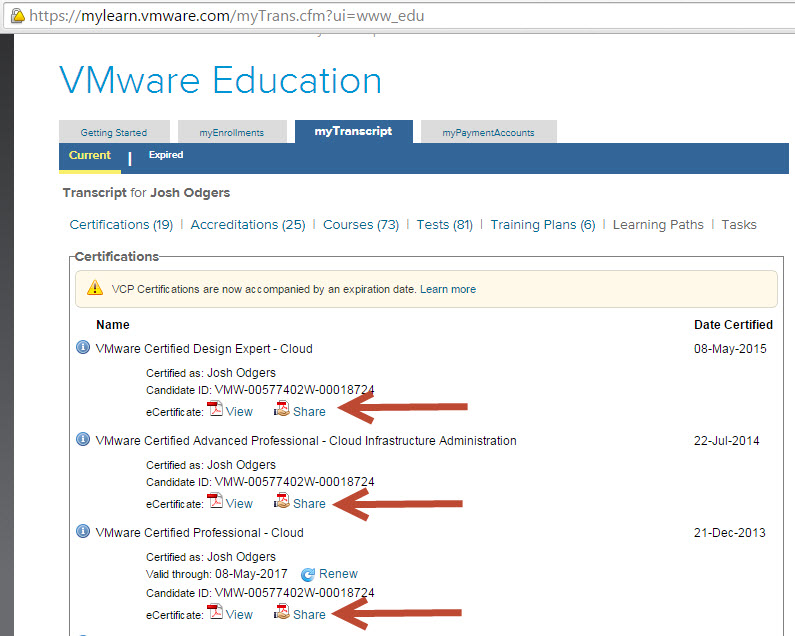
You will also see the “Share” button, what this does is allow you to give a URL to a prospective employer or recruiter for them to validate your certification/s.
To use this facility, simply click the “Share” button and you will be prompted with a window similar to the below:
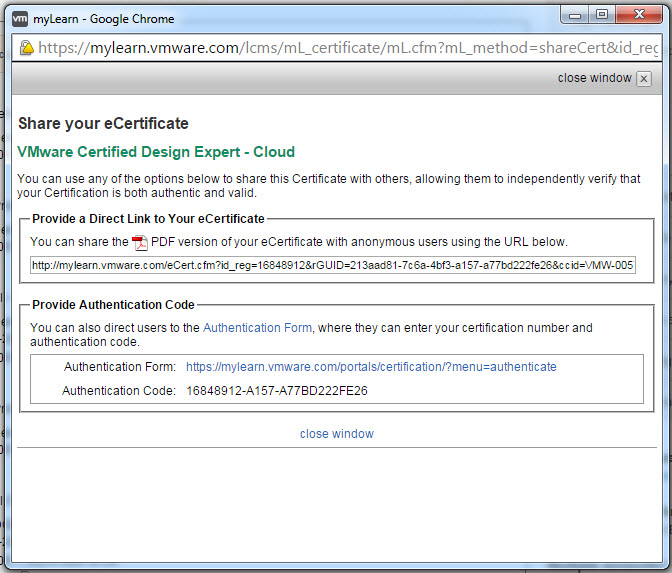
This gives you two options:
1. Share the PDF version of your certificate with anyone by simply copy and pasting the URL.
You will see something similar to this:

2. Share the Certification Authentication form URL and Code and allow anyone to check the current status of your certification.
The following is what you will see when you click the Authentication Form button:

Simply type the random numbers and click Authenticate and you will see something similar to the below: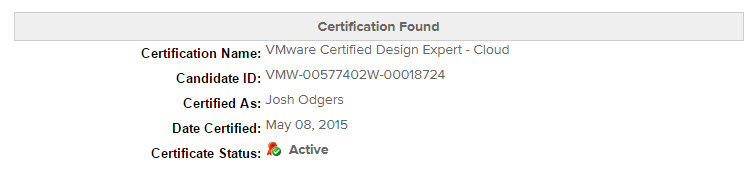
Simple as that!
I hope this post helps potential employers and recruiters validate candidates credentials and stamp out this growing trend of people claiming they have VMware certifications (especially VCDX) when they don’t.
