
As discussed in Part 1 for RF2 and Part 3 for RF3, a critical factor when discussing the resiliency of ADSF is the speed at which compliance with the configured Resiliency Factor can be restored in the event of a drive or node failure.
Let’s do a a quick recap of Part 1 and 3 and then look an an example of the performance of ADSF for a node failure when RF3 with Erasure Coding (EC-X) is used.
Because the rebuild operation (regardless of the configured resiliency factor or data reduction such as EC-X) is a fully distributed operation across all nodes and drives (i.e.: A Many to many operation), it’s both very fast and the workload per node is minimised to avoid bottlenecks and to reduce the impact to running workload.
Remember, the rebuild performance depends on many factors including the size of the cluster, the number/type of drives (e.g.: NVMe, SATA-SSD, DAS-SATA) as well as the CPU generation and network connectivity, but with this in mind I thought I would give an example with the following hardware.
The test bed is a 15 node cluster with a mix of almost 5 year old hardware including NX-6050 and NX-3050 nodes using Ivy Bridge 2560 Processors (Launched Q3, 2013), each with 6 x SATA-SSDs ranging in size and 2 x 10GB network connectivity.
Note: As Erasure Coding requires more computational overhead than RF2 or 3, faster processors would make a significant difference to the rebuild rate as they are used to calculate the parity whereas Resiliency Factor simply copies replicas (i.e.: No parity calculation required).
For this test, the cluster was configured with RF3 and Erasure Coding.
As with previous tests, the node failure is simulated by using the IPMI interface and using the “Power off server – immediate” option as shown below. This is the equivalent of pulling the power out of the back of a physical server.

Below is a screenshot from the Analysis tab in Nutanix HTML 5 PRISM GUI. It shows the storage pool throughput during the rebuild from the simulated node failure.
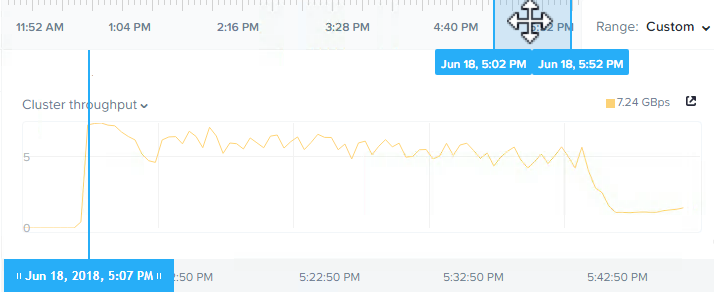
As we can see, the chart shows the rebuild shows a peak of 7.24GBps and sustains over 5GBps throughput until completion. The task itself took just 47mins as shown below from the Chronos Master page which can be found at http://CVM_IP:2011.

So in this example, we see that even with Erasure Coding (EC-X) enabled, Nutanix ADSF is able to rebuild at an extremely fast pace all while providing great capacity savings over RF3.
Summary:
- Nutanix RF3 with or without Erasure Coding is vastly more resilient than RAID6 (or N+2) style architectures
- ADSF performs continual disk scrubbing to detect and resolve underlying issues before they can cause data integrity issues
- Rebuilds from drive or node failures are an efficient distributed operation using all drives and nodes in a cluster regardless of Resiliency Factor or data reduction configuration.
- A recovery from a node failure (in this case, the equivalent of 6 concurrent SSD failures) with Erasure Coding can sustain over 5GBps even on 5yo hardware.
Index:
Part 1 – Node failure rebuild performance
Part 2 – Converting from RF2 to RF3
Part 3 – Node failure rebuild performance with RF3
Part 4 – Converting RF3 to Erasure Coding (EC-X)
Part 5 – Read I/O during CVM maintenance or failures
Part 6 – Write I/O during CVM maintenance or failures
Part 7 – Read & Write I/O during Hypervisor upgrades
Part 8 – Node failure rebuild performance with RF3 & Erasure Coding (EC-X)
Part 9 – Self healing
Part 10: Nutanix Resiliency – Part 10 – Disk Scrubbing / Checksums
You must log in to post a comment.