In part 1, we discussed how data reduction ratios can, and do, vary significantly between customers and datasets and that making assumptions on data reduction ratios, even when vendors provide guarantees, does not protect you from potentially serious problems if the data reduction ratios are not achieved.
In Part 2 we will go through an example of how misleading data reduction guarantees can be.
One HCI manufacturer provides a guarantee promising 10:1 which sounds too good to be true, and that’s because it, quite frankly, isn’t true. The guarantee includes a significant caveat for the 10:1 data reduction:
The savings/efficiency are based on the assumption that you configure a backup policy to take at least one <redacted> backup per day of every virtual machine on every<redacted> system in a given VMware Datacenter with those backups retained for 30 days.
I have a number of issues with this limitation including:
- The use of the word “backup” referring directly/indirectly to data reduction (savings)
- The use of the word “backup” when referring to metadata copies within the same system
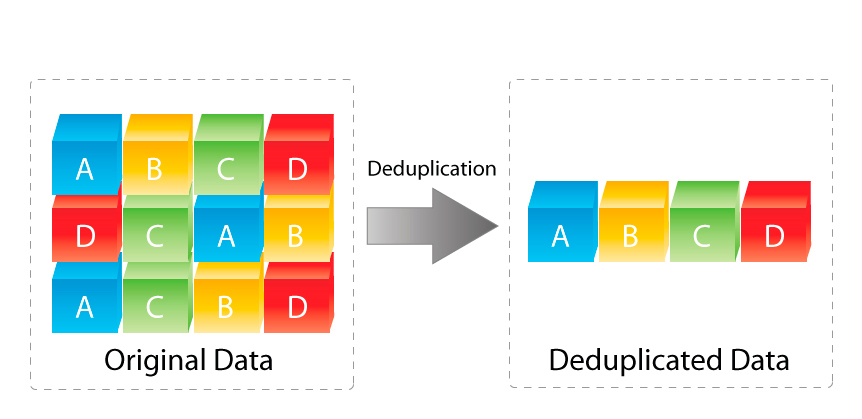
- No actual deduplication or compression is required to achieve the 10:1 data reduction because metadata copies (or what the vendor incorrectly calls “backups”) are counted towards deduplication.
It is important to note, I am not aware of any other vendor who makes the claim that metadata copies ( Snapshots / Point in time copies / Recovery points etc.) are deduplication. They simply are not.
I have previously written about what should be counted in deduplication ratios, and I encourage you to review this post and share your thoughts as it is still a hot topic and one where customers are being oversold/mislead regularly in my experience.
Now let’s do the math on my claim that no actual deduplication or compression is required to achieve the 10:1 ratio.
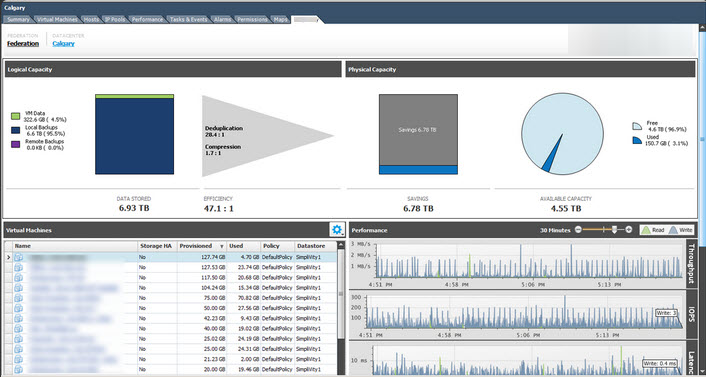
Let’s use a single 1 TB VM as a simple example. Note: The size doesn’t matter for the calculation.
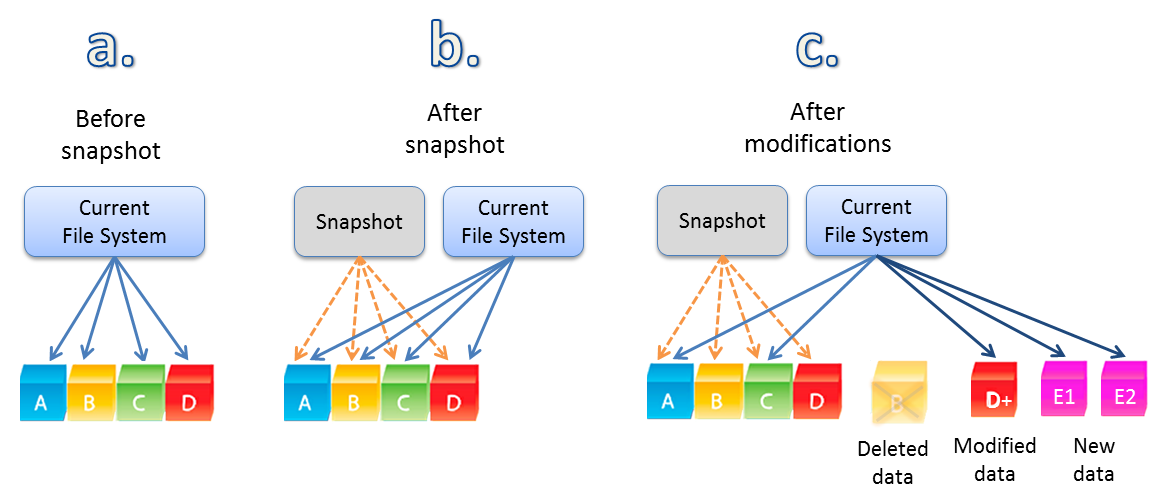
Take 1 “backup” (even though we all know this is not a backup!!) per day for 30 days and count each copy as if it was a full backup to disk, Data logically stored now equals 31TB (1 TB + 30 TB).
The actual Size on disk is only a tiny amount of metadata higher than the original 1TB as the metadata copies pointers don’t create any copies of the data which is another reason it’s not a backup.
Then because these metadata copies are counted as deduplication, the vendor reports a data efficiency of 31:1 in its GUI.
Therefore, Effective Capacity Savings = 96.8% (1TB / 31TB = 0.032) which is rigged to be >90% every time.
So the only significant capacity savings which are guaranteed come from “backups” not actual reduction of the customer’s data from capacity saving technologies.
As every modern storage platform I can think of has the capability to create metadata based point in time recovery points, this is not a new or even a unique feature.
So back to our topic, if you’re sizing your infrastructure based on the assumption of the 10:1 data efficiency, you are in for rude shock.
Dig a little deeper into the “guarantee” and we find the following:
It’s the ratio of storage capacity that would have been used on a comparable traditional storage solution to the physical storage that is actually used in the <redacted> hyperconverged infrastructure. ‘Comparable traditional solutions’ are storage systems that provide VM-level synchronous replication for storage and backup and do not include any deduplication or compression capability.
So if you, for example, had a 5 year old NetApp FAS, and had deduplication and/or compression enabled, the guarantee only applies if you turned those features off, allowed the data to be rehydrated and then compared the results with this vendor’s data reduction ratio.
So to summarize, this “guarantee” lacks integrity because of how misleading it is. It is worthless to any customer using any form of enterprise storage platform probably in the last 5 – 10 years as the capacity savings from metadata based copies are, and have been, table stakes for many, many years from multiple vendors.
So what guarantee does that vendor provide for actual compression and deduplication of the customers data? The answer is NONE as its all metadata copies or what I like to call “Smoke and Mirrors”.
Summary:
“No one will question your integrity if your integrity is not questionable.” In this case the guarantee and people promoting it have questionable integrity especially when many customers may not be aware of the difference between metadata copies and actual copies of data, and critically when it comes to backups. Many customers don’t (and shouldn’t have too) know the intricacies of data reduction, they just want an outcome and 10:1 data efficiency (saving) sounds to any reasonable person as they need 10x less than I have now… which is clearly not the case with this vendors guarantee or product.
Apart from a few exceptions which will not be applicable for most customers, 10:1 data reduction is way outside the ballpark of what is realistically achievable without using questionable measurement tactics such as counting metadata copies / snapshots / recovery points etc.
In my opinion the delta in the data reduction ratio between all major vendors in the storage industry for the same dataset, is not a significant factor when making a decision on a platform. This is because there are countless other substantially more critical factors to consider. When the topic of data reduction comes up in meetings I go out of my way to ensure the customer understands this and has covered off the other areas like availability, resiliency, recoverability, manageability, security and so on before I, quite frankly waste their time talking about table stakes capability like data reduction.
I encourage all customers to demand nothing less of vendors than honestly and integrity and in the event a vendor promises you something, hold them accountable to deliver the outcome they promised.