
When virtualizing Exchange, we not only have to consider the Compute (CPU/RAM) and Network, but also the storage to provide both the capacity and IOPS required.
However before considering IOPS and capacity, we need to decide how we will provide storage for Exchange as storage can be presented to a Virtual Machine in many ways.
This post will cover the different ways storage can be presented to ESXi and used for Exchange while subsequent posts will cover in detail each of the options discussed.
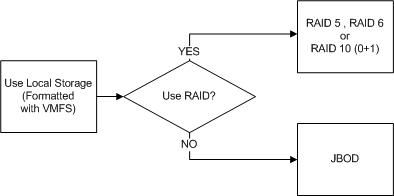
First lets discuss Local Storage.
What I mean by Local Storage is SSD/HDDs within a physical ESXi hosts that is not shared (e.g.: Not accessible by other hosts).
This is probably the most basic form of storage we can present to ESXi and apart from the Hypervisor layer could be considered similar to a physical Exchange deployment.
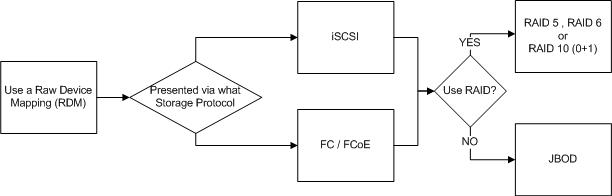
Next lets discuss Raw Device Mappings.
Raw Device Mappings or “RDMs” are where shared storage from a SAN is presented through the hypervisor to the guest as a native SCSI device and enables.
For more information about Raw Device Mappings, see: About Raw Device Mappings
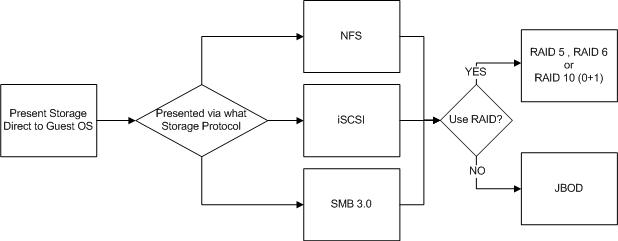
The next option is Presenting Storage direct to the Guest OS.
It is possible and sometime advantageous to presents SAN/NAS storage direct to the Guest OS via NFS , iSCSI or SMB 3.0 and bypasses the hyper-visor all together.
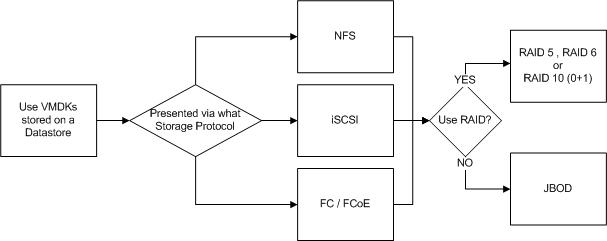
The final option we will discuss is “Datastores“.
Datastores are probably the most common way to present storage to ESXi. Datastores can be Block or File based, and presented via iSCSI , NFS or FCP (FC / FCoE) as of vSphere 5.5.
Datastores are basically just LUNs or NFS mounts. If the datastore is backed by a LUN, it will be formatted with Virtual Machine File System (VMFS) whereas NFS datastores are simply NFS 3 mounts with no formatting done by ESXi.
For more information about VMFS see: Virtual Machine File System Technical Overview.
What do all the above options have in common?
Local storage, RDMs, storage presented to the Guest OS directly and Datastores can all be protected by RAID or be JBOD deployments with no data protection at the storage layer.
Importantly, none of the four options on their own guarantee data protection or integrity, that is, prevent data loss or corruption. Protecting from data loss or corruption is a separate topic which I will cover in a non Exchange specific post.
So regardless of the way you present your storage to ESXi or the VM, how you ensure data protection and integrity needs to be considered.
In summary, there are four main ways (listed below) to present storage to ESXi which can be used for Exchange each with different considerations around Availability, Performance, Scalability, Cost , Complexity and support.
1. Local Storage (Part 8)
2. Raw Device Mappings (Part 9)
3. Direct to the Guest OS (Part 10)
4. Datastores (Part 11)
In the next four parts, each of these storage options for MS Exchange will be discussed in detail.
Back to the Index of How to successfully Virtualize MS Exchange.



