I am pleased to announce that Microsoft have approved Nutanix latest ESRP (Exchange Storage Review Program) submission for a 50,000 user deployment of MS Exchange on Nutanix NX-8150 all flash platform running the next generation hypervisor, AHV!
What’s unique about this you might ask?
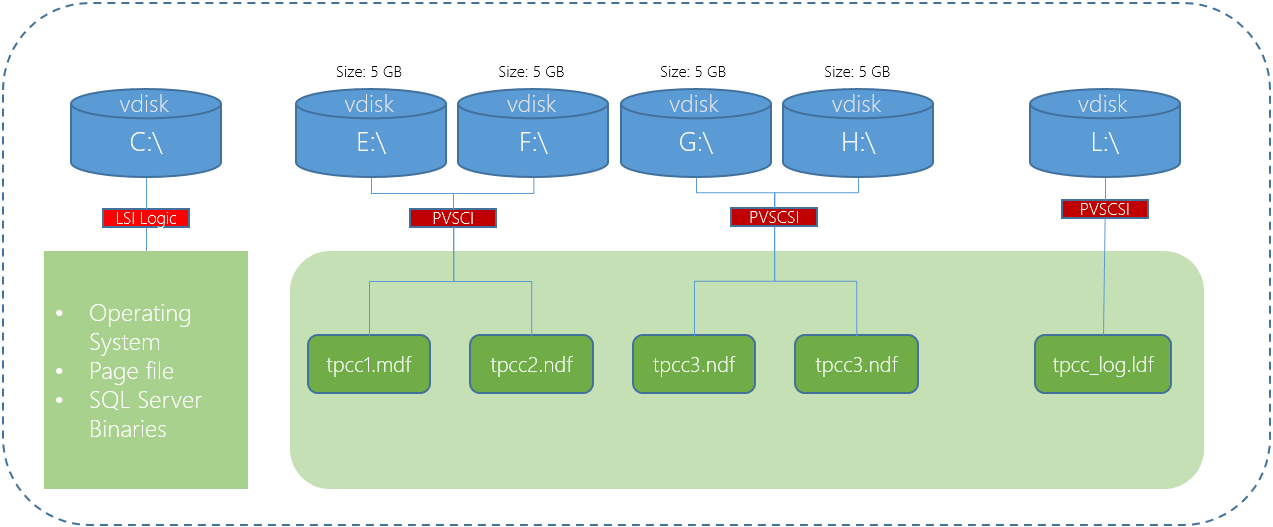
- It’s the first hyper-converged (HCI) all flash ESRP solution (to compliment Nutanix existing Hybrid ESRP solutions for 24k users on Hyper-V and 30k users on AHV)
- The first multiple Exchange VM per node solution!!
- The first ESRP to provide MS Exchange Server role requirements calculator solution design
- The solution was performance tested/validated with N-1 nodes to simulate performance in the event a node had failed and was not replaced
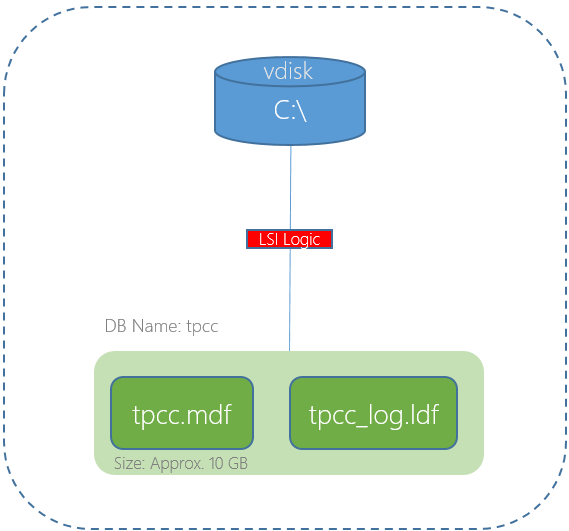
- The solution supports the 1GB mailboxes without any assumed data reduction from compression, deduplication or Erasure Coding (EC-X)
The last point is key. Many vendors/solutions assume high data reduction ratios when sizing which adds risk to a project as I explained in Sizing infrastructure based on vendor Data Reduction assumptions. Nutanix (and me personally) rather give customers a guaranteed business outcome and while our data reduction is very effective especially for MS Exchange data, it can and does vary between customers. An ESRP should be a guaranteed outcome, and that’s what this unique ESRP from Nutanix delivers.
A major problem with many, if not most ESRP submissions is that they are not real world solutions, just storage platforms which can deliver high enough IOPS to potentially support a real world solution.
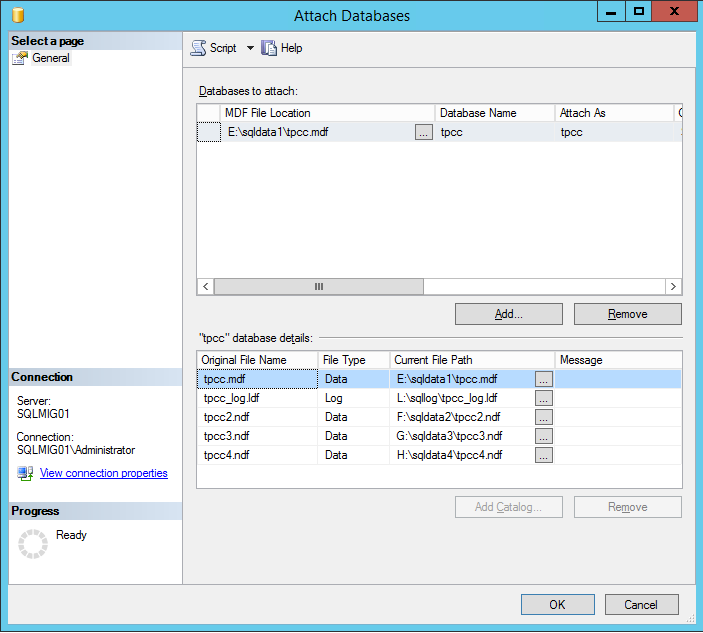
When designing the solution I planned to put forward for ESRP, I used an actual real world design for a Nutanix customer and ensures it was sized to be 100% real world.
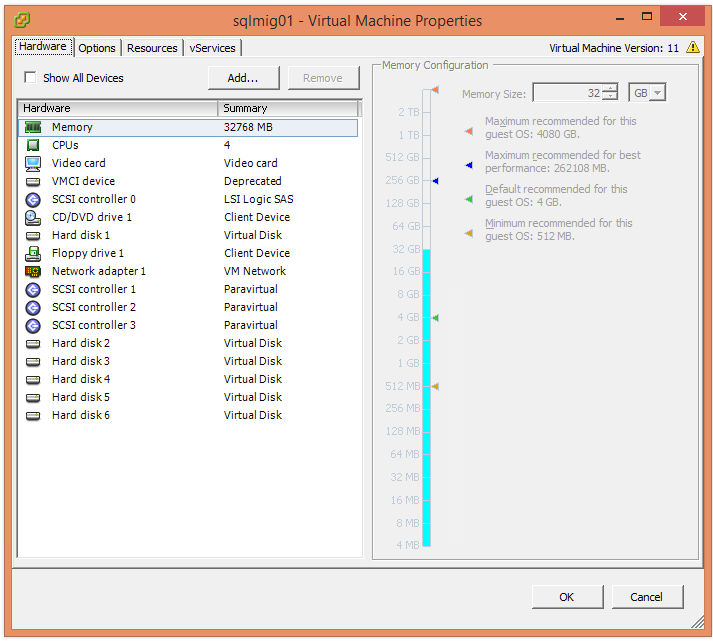
For example, from a compute perspective the solution was sized with no CPU overcommitment and within the recommended maximum of 24 CPUs both of which ensure optimal CPU performance.
CPU sizing also ensures Exchange VMs fit within the NUMA node of the Nutanix node which ensures optimal memory performance, which is another key area to ensure optimal Exchange performance.
In addition, The VMs are sized to be under the Microsoft recommended CPU utilization threshold for a “Worst Failure Mode” of ≤ 80 percent.
From a real world perspective, MS Exchange is dependant on Active Directory. As a result the solution is also sized to support all the required Active Directory Global Catalog cores running on the same infrastructure.
From an availability and resiliency perspective, the solution is sized for N+1 at the infrastructure layer to compliment the N+1 at the MS Exchange DAG layer. This delivers customers a solution which has protection from multiple concurrent failures which is essential for Mission Critical applications.
In the real world, things change and having a solution which scales to support more users, more messages per day and greater mailbox capacity is essential.
The Nutanix NX-8150 All Flash ESRP discusses a scalable and repeatable model where the solution can be increased in size from supporting 1 GB mailboxes to >2 GB simply by choosing (configure to order) 3.84 TB drives vs. the 1.92 TB drives tested for this solution.
Another option is when the storage capacity is reaching a high threshold such as 80%+, customers can non disruptively add storage nodes to expand capacity. This can be done without any change at the OS or MS Exchange application layer and new capacity (and performance!) is available instantly.
Did you know Nutanix allows mixing all-flash & hybrid? This means the most active data (e.g.: Most recent email) is running in an all flash configuration and older mail is automatically and transparently migrated to the lower cost hybrid nodes.
From a storage performance perspective, the solution was tested with in-line compression enabled which is Nutanix official recommendation for MS Exchange as it provides excellent data reduction with no significant overheads.
Another focus are for Nutanix in the real world is reducing CAPEX and OPEX. A great example of this is the entire solution (excluding networking) uses just 10 rack units (RUs) per datacenter. While other vendors storage ESRPs will claim lower RU requirements, they excluding the physical servers required for the solution. Nutanix is advising the requirements for the compute and storage for the solution to be totally transparent.
This means the solution does not require a large investment in your datacenter or co-location and is cost effective to power and cool making the solution environmentally friendly as well.
From a performance perspective, the Nutanix solution was tested in an N-1 configuration to show the performance which can be achieved after the failure of a node within the cluster.
Even with a failed node, the solution achieves excellent performance with average database read and log write latency in the low 1ms range sustained for the 24 stress test required for ESRP submissions.
A few performance highlights:
- Nutanix achieved an average of 5172 IOPS per MS Exchange Jetstress instance with just 4 threads!
- Database read latency avg of just 1.05ms
- Log write latency avg of just 1.21ms
- Database backup performance of 215MB/sec per database which equates to more than 1.7GBps per node!
While the achieved performance vastly exceeds the requirements for Exchange, the key factor is the reduced CPU WAIT time achieved which results in much greater CPU efficiency than a physical Exchange server with JBOD storage. Meaning a virtualised exchange server on Nutanix (even hybrid systems) is more efficient than Microsoft Preferred architecture using physical servers and JBOD storage.
You may be asking yourself, why does this matter? The answer is simple. MS Exchange becomes inefficient when scaled up beyond 24 cores so the more efficient the usage of those cores, the more users, messages per day and better user experience can be achieved without scaling up or adding more servers.
So without further delay, I have provided the direct link to the document below for you convenience.
Nutanix ESRP – NX-8150-G5 All Flash 50,000 Users