At VMware vForum Sydney this week I presented “Taking vSphere to the next level with converged infrastructure”.
Firstly, I wanted to thank everyone who attended the session, it was a great turnout and during the Q&A there were a ton of great questions.
One part of the presentation I got a lot of feedback on was when I spoke about Performance and Scaling and how this is a major issue with traditional shared storage.
So for those who couldn’t attend the session, I decided to create this post.
So lets start with a traditional environment with two VMware ESXi hosts, connected via FC or IP to a Storage array. In this example the storage controllers have a combined capability of 100K IOPS.

As we have two (2) ESXi hosts, if we divide the performance capabilities of the storage controllers between the two hosts we get 50K IOPS per node.
This is an example of what I have typically seen in customer sites, and day 1, and performance normally meets the customers requirements.
As environments tend to grow over time, the most common thing to expand is the compute layer, so the below shows what happens when a third ESXi host is added to the cluster, and connected to the SAN.
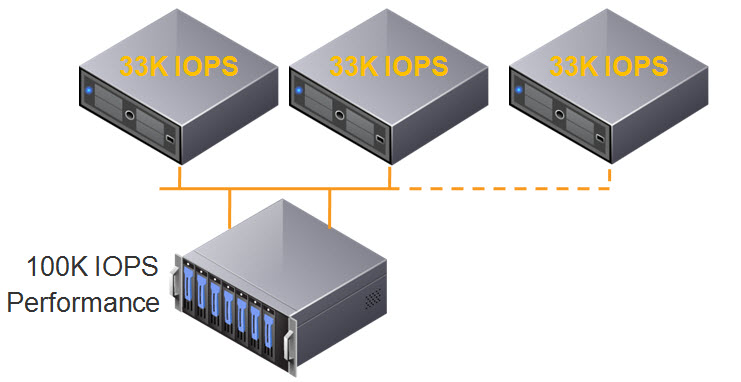
The 100K IOPS is now divided by 3, and each ESXi host now has 33K IOPS.
This isn’t really what customers expect when they add additional servers to an environment, but in reality, the storage performance is further divided between ESXi hosts and results in less IOPS per host in the best case scenario. Worst case scenario is the additional workloads on the third host create contention, and each host may have even less IOPS available to it.
But wait, there’s more!
What happens when we add a forth host? We further reduce the storage performance per ESXi host to 25K IOPS as shown below, which is HALF the original performance.
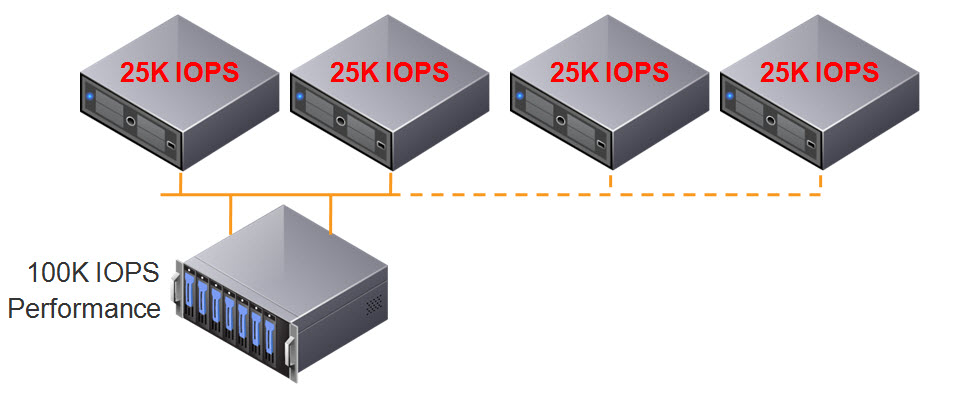
At this stage, the customers performance is generally significantly impacted, and there is no easy or cost effective resolution to the problem.
….. and when we add a fifth host? We continue to reduce the storage performance per ESXi host to 20K IOPS which is less than half its original performance.
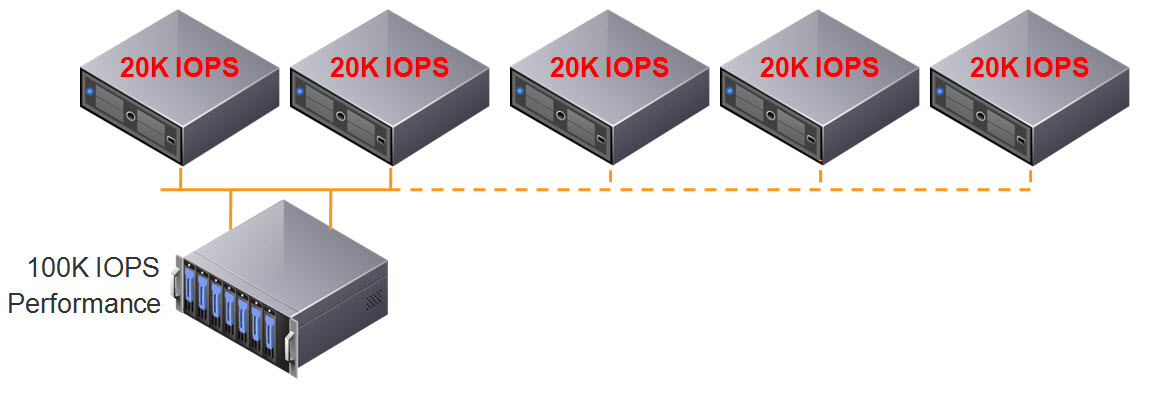
So at this stage, some of you may be thinking, “yeah yeah, but I would also scale my storage by adding disk shelves.”
So lets add a disk shelf and see what happens.
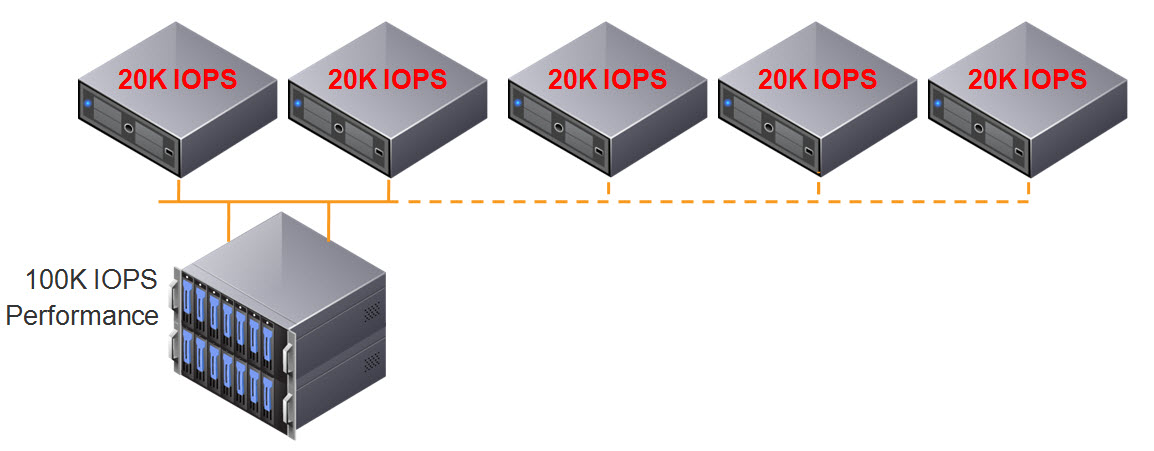
We still only have 100K IOPS capable storage controllers, so we don’t get any additional IOPS to our ESXi hosts, the result of adding the additional disk shelf is REDUCED performance per GB!
Make sure when your looking at implementing, upgrading or replacing your storage solution that it can actually scale both performance (IOPS/throughput) AND capacity in a linear fashion,otherwise your environment will to some extent be impacted by what I have explained above. The only ways to avoid the above is to oversize your storage day 1, but even if you do this, over time your environment will appear to become slower (and your CAPEX will be very high).
Also, consider the scaling increments, as a solutions ability to scale should not require you to replace controllers or disks, or have a maximum number of controllers in the cluster. it also should scale in both small, medium and large increments depending on the requirements of the customer.
This is why I believe scale out shared nothing architecture will be the architecture of the future and it has already been proven by the likes of Google, Facebook and Twitter, and now brought to market by Nutanix.
Traditional storage, no matter how intelligent does not scale linearly or granularly enough. This results in complexity in architecture of storage solutions for environments which grow over time and lead to customers spending more money up front when the investment may not be realised for 2-5 years.
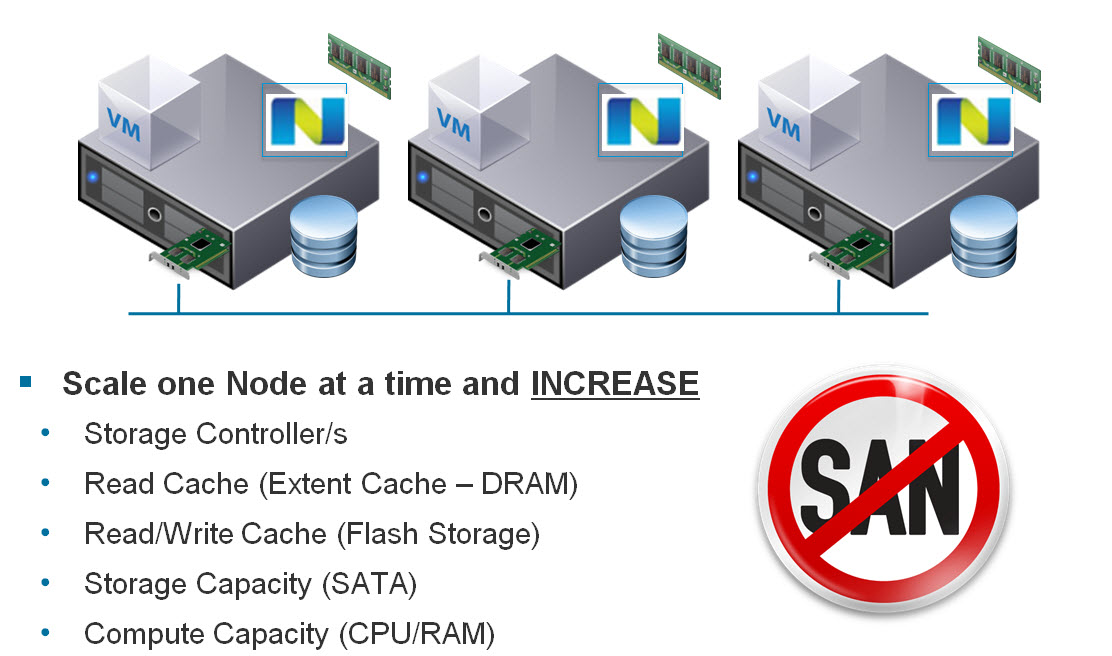
I’d prefer to be able to Start small with as little as 3 nodes, and scale one node at a time (regardless of node model ie: NX1000 , NX3000 , NX6000) to meet my customers requirements and never have to replace hardware just to get more performance or capacity.
Here is a summary of the Nutanix scaling capabilities, where you can scale Compute heavy, storage heavy or a mix of both as required.