In addition to the increased effective SSD (and SATA) tier capacity gained by using Erasure Coding (EC-X) which was announced at the Nutanix .NEXT conference earlier this year, the upcoming NOS (Nutanix Operating System) 4.5 is providing a yet another effective capacity increase for the SSD tier.
Here’s how it works:
The below 4 node cluster has 3 VMs actively using data (known as extents) represented by the A,B,C blocks. This is a very simplified example as VMs will have potentially hundreds or thousands of extents distributed throughout a cluster.
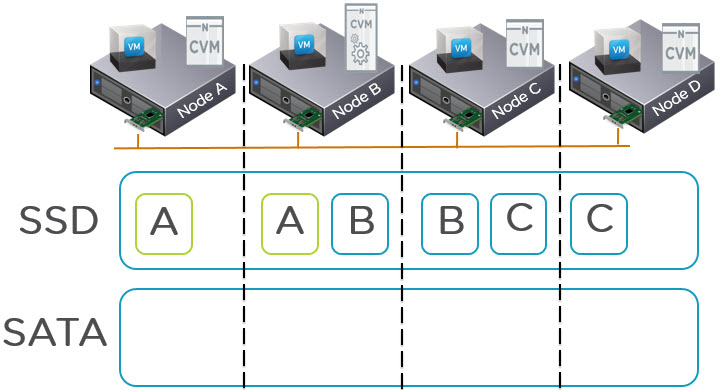
What we can see in the above diagram is two copies of each piece of data as this is an RF2 deployment. The VM on Node A is using extent A, the VM on Node B is using extent B and the VM on Node C is using extent C.
Because the VMs are using Extents A,B and C, they all remain within the SSD tier including the replicas distributed throughout the cluster. When these extents become cold they will be dynamically moved to the SATA tier.
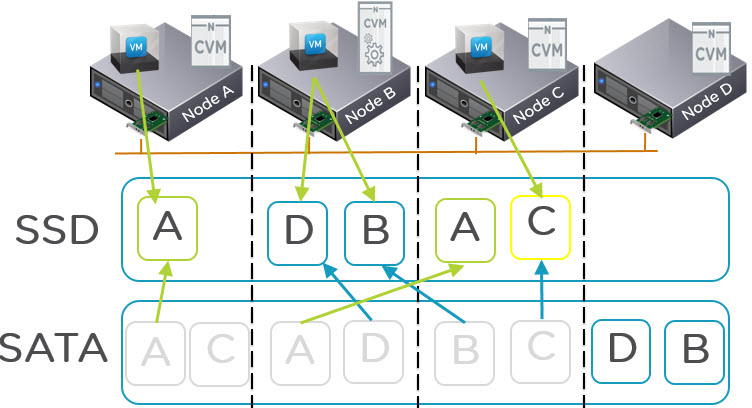
What is changing in NOS 4.5 is the Nutanix tiering solution called ILM (Intelligent Lifecycle Management) now perform up-migrations (from SATA to SSD) on a per extent basis which means replicas are treated independent of each other. What this means is the hot extents will up-migrate to SSD on the node where the VM is running (via Data Locality) giving all flash performance while the replicas distributed throughout the cluster will remain in the SATA tier as shown below:
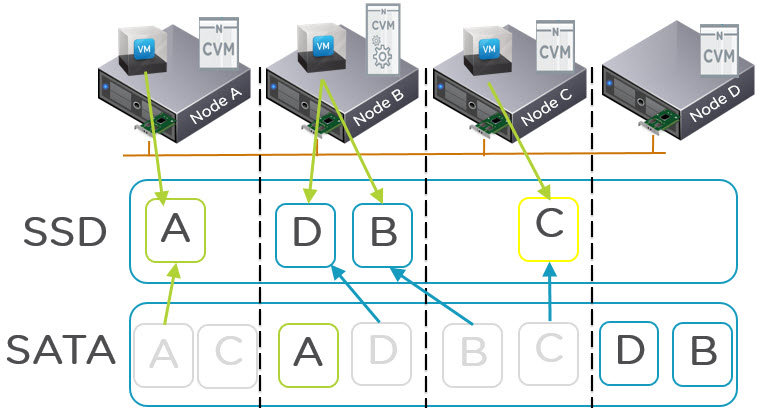
As we can see in the above diagram, all copies of A,B,C and D were in the SATA tier. Then the VM on node A started frequently reading from data A and the local extent is therefore up-migrate to SSD.
For the VM on node B, it started frequently accessing data D and B. Data D was up-migrated from local SATA and data B was up-migrated AND localized as it was residing on a remote node. The VM on node C also up-migrated from local SATA the same as VM on node A.
Now we can see that out of the 8 extents, we have 4 which have me up-migrated and localized (where required) and 4 which remain in the low cost SATA tier.
As a result the SSD tiers effective capacity is doubled for RF2 and tripled for RF3. So this means for customers using RF2, the active working set can potentially double while still providing all flash performance.
If data is frequently being overwritten NDFS will detect this and up-migrate both the local and remote copy/copies to ensure write I/O is always serviced by the SSD tier. The below diagram shows Data A being up-migrated to node C SSD tier ready to service the redundant replicas for any write I/O.
As typical mixed workload environments have a higher Read vs Write ratio e.g.: 70/30 the benefits of only up-migrating one extent when it becomes hot is effective for a large percentage of the I/O.
Even in the event the Read vs Write Ratio is reversed e.g.: 30/70 which is typical for VDI environments, the new ILM process will still provide a significant effective increase of the SSD tier by only up-migrating one out of two extents. It should be noted for VDI solutions, VAAI-NAS already provides huge data reduction savings thanks to intelligent cloning and as a result it is not uncommon to find large VDI deployments on Nutanix using only the SSD tier.
Summary:
NOS 4.5 delivers Double or Triple (for RF3) the effective SSD tier capacity in addition to data reduction savings from technologies such as deduplication, compression and Erasure Coding (EC-X). This feature is like most things with Nutanix is hypervisor agnostic!
Not bad for a free software upgrade huh!
Related Posts:
1. Scaling Hyper-converged solutions – Compute only.
2. Advanced Storage Performance Monitoring with Nutanix
3. Nutanix – Improving Resiliency of Large Clusters with Erasure Coding (EC-X)
4. Nutanix – Erasure Coding (EC-X) Deep Dive