
This past week at Nutanix .NEXT, Acropolis was officially announced although it has actually been available and running in many customer environments (1200+ nodes globally) for a long time.
One of the new features is VM High Availability.
As with everything Nutanix, VM HA is a very simple yet effective feature. Let’s go through how to configure HA via the Acropolis/PRISM HTML 5 interface.
As shown below, using the “Options” menu represented by the cog, there is an option called “Manage VM High Availability”.
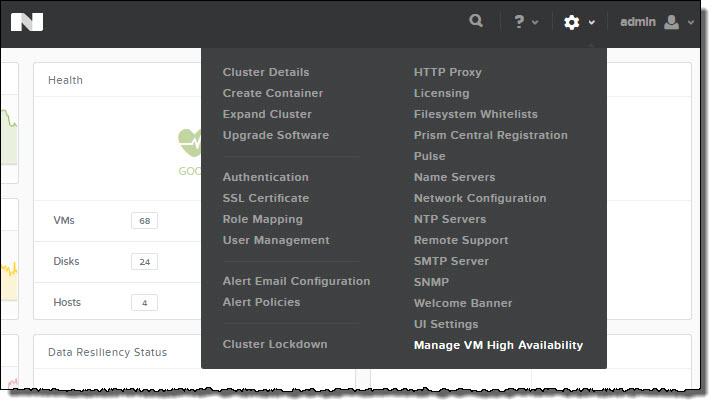
The Manage VM High Availability has 2 simple options shown below:
1. Enable VM High Availability (On/Off)
2: Best Effort / Reserve Space
Best Effort works as you might expect where in the event of a node failure, VMs are powered on throughout the cluster if resources are available.
In the event resources e.g.: Memory, are not available then some/all VMs may not be powered on.
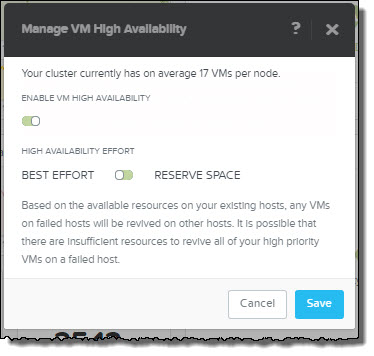
Reserve Space also works as you might expect by reserving enough compute capacity within the cluster to tolerate either one or two node failures. If RF2 is configured then one node is reserved and if RF3 is in use, two nodes are reserved.
Pretty simple right!
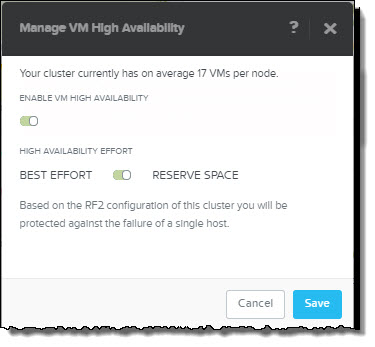
The best part about Reserve Space is its like “Host failures cluster tolerates” in vSphere, however without using the potentially inefficient slot size algorithm.
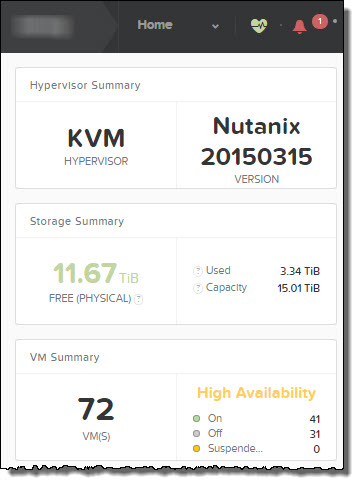
Once HA is enabled, it appears on the Home screen of PRISM and gives a summary of the VMs which are On,Off and Suspended as shown below.
HA can also be enabled/disabled on a per VM basis via the VMs tab. Simply highlight the VM and click “Update” as shown below.
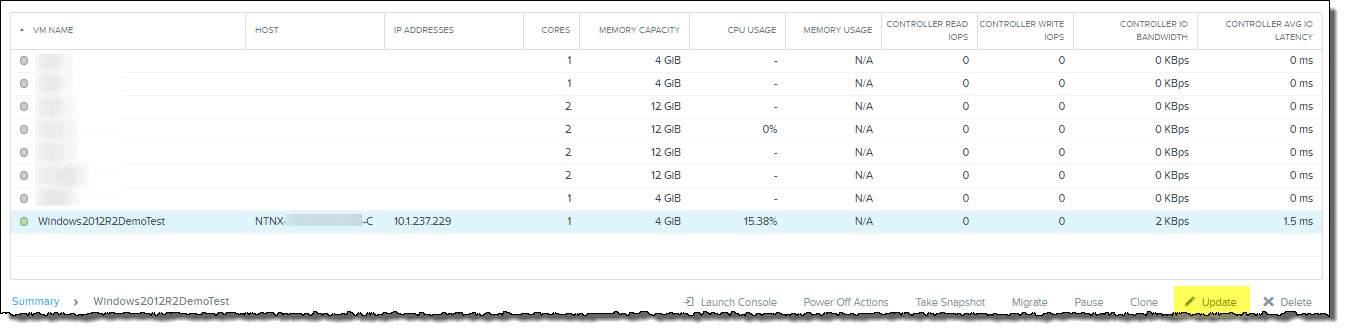
Then you will see the “Update VM” popup appear. Then simply Enable HA.
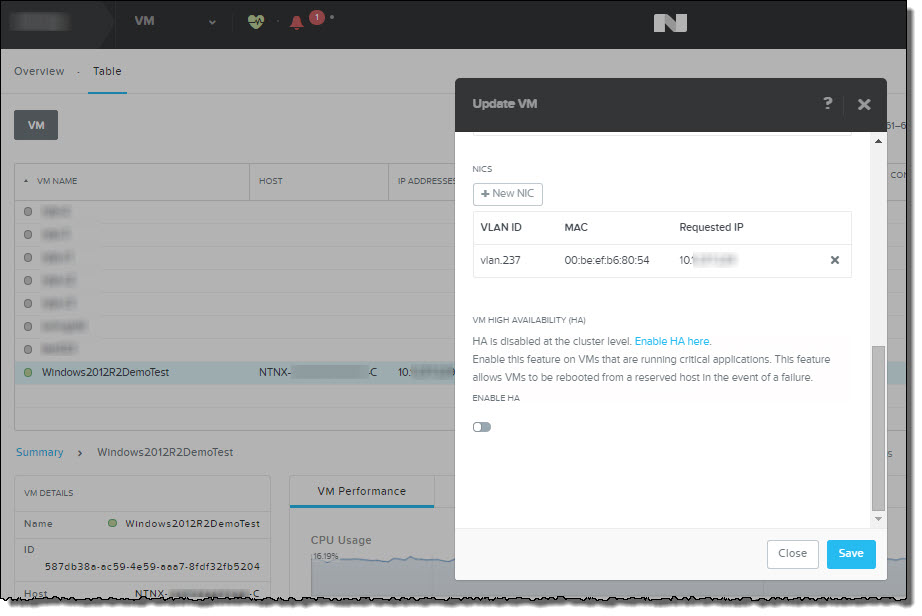
In the above screenshot you can see that the popup also warns you if HA is disabled at the cluster level and allows you to jump straight to the Manage VM High Availability configuration menu.
So there you have it, Acropolis VM High Availability, simple as that.
Related Articles:
1. Acropolis: Scalability
2. What’s .NEXT? – Acropolis!
3. What’s .NEXT? – Erasure Coding!
Great post….clear and to the point. Quick question – I haven’t been able to find anything regarding ‘DRS Affinity/Anti-Affinity’ (like in vSphere), or ‘Metro-DRS’ (vMotion over a higher-latency link). Are these features not available in Nutanix Acropolis?
Hi Joe, as of the current GA version, Acropolis does not have an equivalent to DRS rules. However, if you migrate a VM to an Acropolis node, it will not move off that node, thus achieving the same outcome. There are numerous features like Fully Automated Load balancing, VM placement, enhanced migration etc coming to Acropolis in the short term so stay tuned.
Specifically regarding vMotion over high latency links, we don’t have a maximum latency restriction for Acropolis migration, but in saying that, even with vSphere you wouldn’t want to migrate anything critical (high memory/iops) over a high latency link due to the high impact to the VM/Application. What sort of latency do you have in your environment?
Cheers
Hey Josh,
Thanks again for the response. We’re looking at about 12-13ms latency between our two sites. We don’t really do a whole lot of migrations between our two sites now, but it’s definitely nice to do it when we can.
As far as the DRS stuff is concerned, those are all features I’d definitely be more interested in knowing when they are coming. We’re on the verge of purchasing one of these for a new solution we have coming onboard, but not having the features you mentioned is kind of a buzz kill. However, I know that features can be added in just by firmware upgrades, so that’s great. Timing would be the only thing I’d be concerned with.