
In Part 1, we discussed how to size Exchange VMs. In Part 2 we will focus on the different vCPU configuration options for Exchange VMs.
Before we start, I wanted to clarify that regardless of if an ESXi host has HT enabled or not, ESXi will always attempt to schedule vCPUs onto Physical Cores. As a result, in most cases vCPUs are equivalent to physical cores but in the event of contention, HTs help prevent CPU ready which can degrade the performance of applications such as Exchange.
Therefore it is recommended to leave HT enabled in virtual deployments.
Now let’s discuss the two main types of vCPU configurations, they are:
1. Wide and Flat
2. PreferHT
Starting with “Wide and Flat“, this refers to a VM which is configured with multiple virtual sockets with 1 core per virtual socket, as shown below.
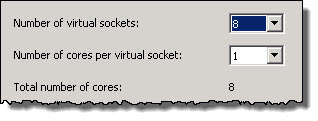
Wide and Flat is recommended for Exchange VMs whose CPU requirements exceed that of a NUMA node as the benefit of the Exchange VM to have more CPU power generally exceeds the value of NUMA memory locality.
However, I still recommend scaling out to at least 4 Exchange VMs before scaling up as discussed in Part 1.
With Wide and Flat configurations in vSphere 5.0 or later, VMs automatically have vNUMA enabled where VMs are 8 vCPUs or higher which means ESXi presents Virtual NUMA to the Guest Operating System which means CPU and Memory can be optimally placed to benefit from NUMA locality.
See the following post on Checking vNUMA topology.
The below shows an example of a Dual Socket ESXi host with 2 x 8 core processors with HT enabled and a VM with 16 vCPUs in a Wide and Flat configuration. This VM is scheduled with a preference to physical cores and only onto HT cores if physical cores are monopolized.

Wide and Flat is great for environments where Exchange VMs are dedicated to ESXi hosts OR the host is running other workloads with low vCPU requirements, such as Domain Controllers as the Exchange VM will generally get scheduled onto Physical Cores giving it maximum performance, while smaller less CPU intensive VMs can operate with HT cores without issue.
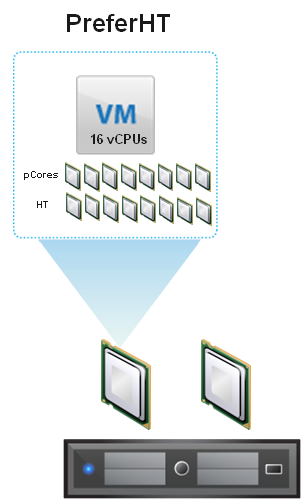
Next lets discuss “PreferHT“. This refers to a VM which is configured to the same number of vCPUs as logical cores (Physical + HT) exist within the NUMA node.
The below shows an example of a Dual Socket ESXi host with 2 x 8 core processors with HT enabled with a VM configured with 16 vCPUs with PreferHT enabled. This VM is getting the full performance of a physical socket.
“PreferHT” can be enabled in two ways, Per VM or Per Host.
I recommend enabling only on a Per VM basis, as this only needs to be done for large business critical applications such as MS Exchange.
To enable “PreferHT” on a per VM basis, Right-click the VM, Edit Settings, Options tab , General then click Configuration Parameters simply add the numa.vcpu.preferHT=TRUE to the advanced configuration file as shown below.
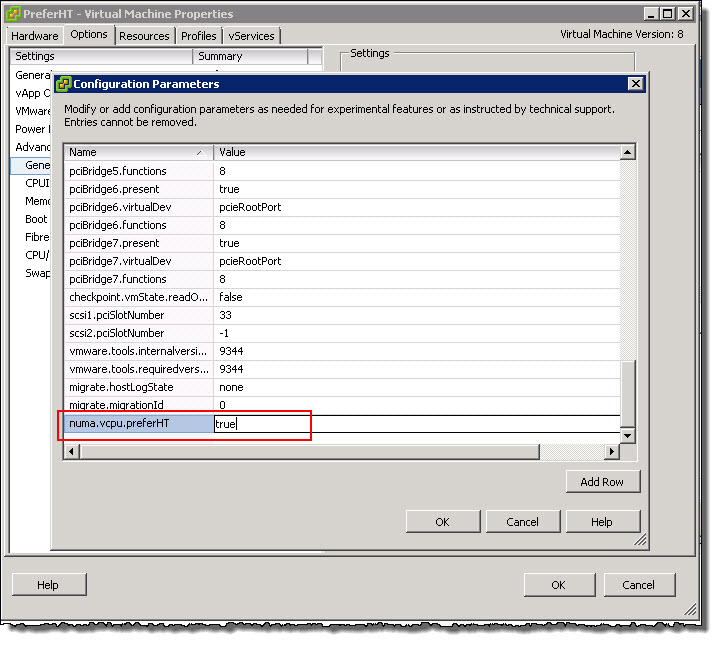
This process is also described in VMware KB 2003582 as well as detailing the way to enable PreferHT for all VMs which as I mentioned I don’t recommend.
PreferHT can be a good option to get the most performance for your Exchange VM without monopolizing all of the host resources, especially in environments where Exchange runs in the same cluster with other VM workloads. PreferHT also gives optimal memory performance as the Exchange VM will benefit from NUMA locality, meaning the CPU and Memory operate within a NUMA node, reducing latency between CPU and Memory.
As Exchange 2013 is especially CPU and RAM heavy, this can provide significant benefits where the Exchange VMs compute requires fit within a NUMA node. However if the compute requirements are greater than the NUMA node, a Wide and Flat configuration is recommended.
Note: The PreferHT configuration allows Exchange VMs to get the full performance of a physical processor and therefore the full SPECint2006 rate for the CPU.
Rule: Take into account Physical CPU core count!
The vCPU configuration should also take into account the underlying physical CPUs as mismatching vCPU numbers to physical CPU size can result in degraded performance.
For example: If you have an ESXi host with 8 core processors, the optimal vCPU configurations are 1,2,4 & 8 vCPUs as these are evenly divisible with 8.
For further information see VMware KB1026063.
Rules of Thumb:
1. If your Exchange VM requirements are ≤ 80% of your NUMA node, use Wide and Flat.
2. If your Exchange VM requirements are > your NUMA node, use Wide and Flat.
3. If you want to maximize your Exchange VMs performance in a mixed workload environment without monopolizing your hosts CPU resources AND the Exchange sizing tool reports CPU utilization for the Exchange VM at ≥80% of the SPECint2006 rate for your processor, use PreferHT.
4. In all other cases use Wide and Flat.
Recommendations:
1. Use “Wide and Flat” CPU configuration by default
2. Size Exchange VMs with your NUMA node in mind
3. Ensure HT is ENABLED on the ESXi host
Back to the Index of How to successfully Virtualize MS Exchange.