In part 1 we discussed the ability of Nutanix AOS to rebuild Resiliency Factor 2 (RF2) from a node failure in a fast and efficient manner thanks to the Acropolis Distributed Storage Fabric (ADSF) while part 2 showed how a storage container can be converted from RF2 to RF3 to further improve resiliency and how fast the process completed.
As with Part 2, we’re using a 12 node cluster and the breakdown of disk usage per node is as follows:
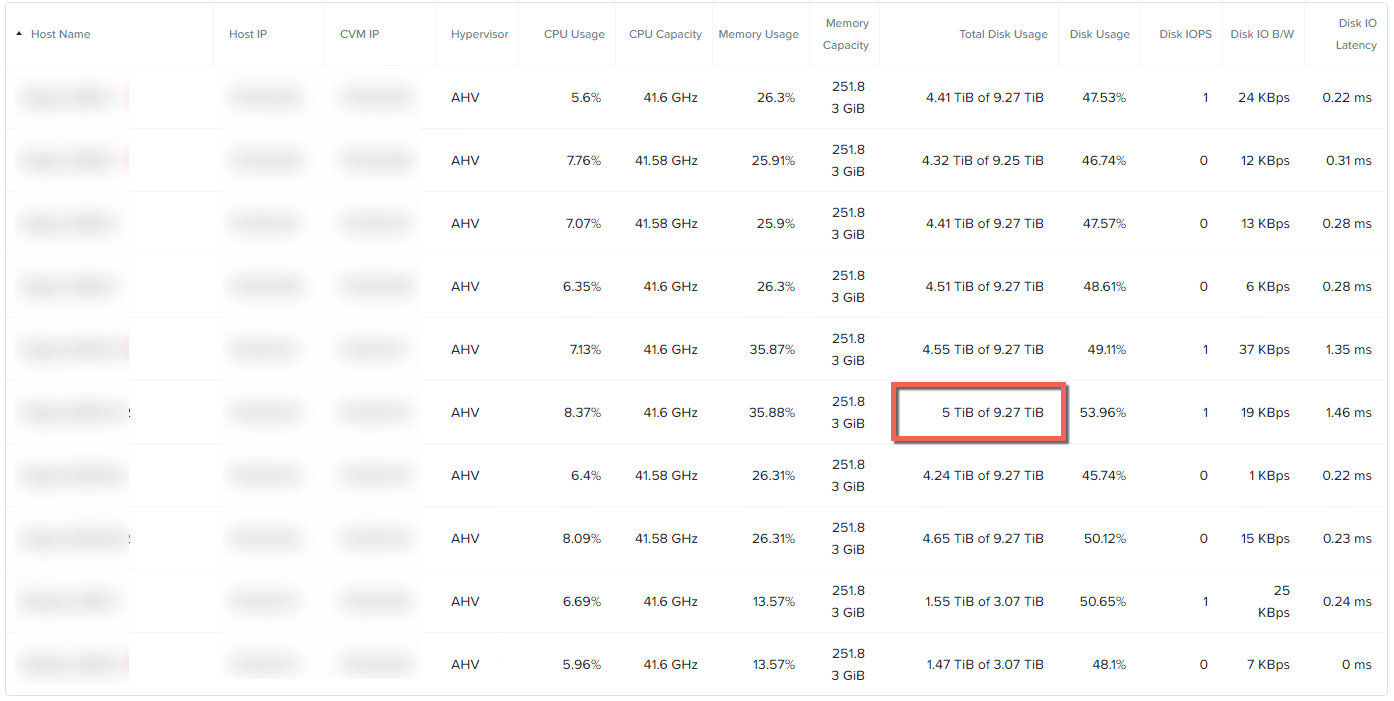
The node I’ll be simulating a failure on has 5TB of disk usage which is very similar to the capacity usage in the node failure testing in Part 1. It should be noted that as the cluster is now only 12 nodes, there are less controllers to read/write from/too as compared to Part 1.
Next I accessed the IPM Interface of the node and performed a “Power Off – Immediate” operation to simulate the node failure.
The following shows the storage pool throughput for the node rebuild which completed re-protecting the 5TB of data in approx 30mins.
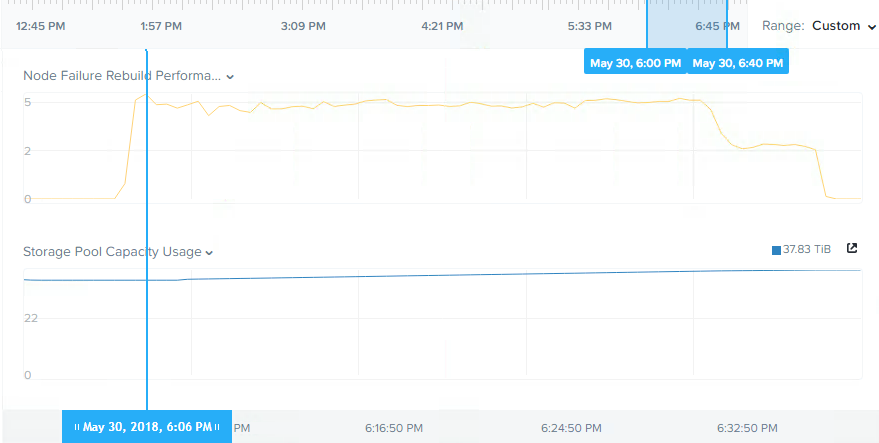
Looking at the results at first glance, re-protecting in around 30 mins for 5TB of data, especially on 5yo hardware is pretty impressive, especially compared to SANs and other HCI products, but I felt it should have been faster so I did some investigation.
I found that the cluster was in an imbalanced state at the time I simulated the node failure and therefore not all nodes could contribute to the rebuild (from a read perspective) like they would under normal circumstances because they had little/no data on them.
The reason the cluster was in the un-balanced state is due to my having been performing frequent/repeated node failure simulations and I did not wait for disk balancing to complete after adding nodes back to the cluster before simulating the node failure.
Usually a vendor would not post sub-optimal performance results, but I strongly feel that transparency is key and while unlikely, it is possible to get in situations where a cluster is unbalanced and if a node failure occurred during this unlikely scenario it’s important to understand how that may impact resiliency.
So I ensured the cluster was in a balanced state and then re-ran the test and the result is shown below:
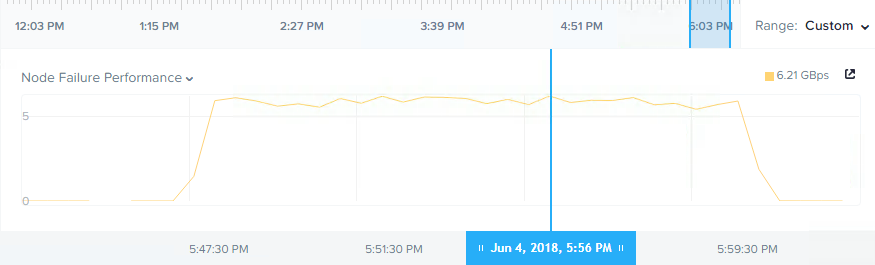
We can now see over 6GBps throughput compared to around 5Gbps, an improvement of over 1GBps, and a duration of approx 12mins. We also can see there was no drop in throughput as we previously saw in the unbalanced environment. This is due to all nodes being able to participate for the duration of the rebuild as they all had an even amount of data.
Summary:
- Nutanix RF3 is vastly more resilient than RAID6 (or N+2) style architectures
- ADSF performs continual disk scrubbing to detect and resolve underlying issues before they can cause data integrity issues
- Rebuilds from drive or node failures are an efficient distributed operation using all drives and nodes in a cluster
- A recovery from a >4.5TB node failure (in this case, the equivalent of 6 concurrent SSD failures) around 12mins
- Unbalanced clusters still perform rebuilds in a distributed manner and can recover from failures in a short period of time
- Clusters running in a normal balanced configuration can recover from failures even faster thanks to the distributed storage fabric built in disk balancing, intelligent replica placement and even distribution of data.
Index:
Part 1 – Node failure rebuild performance
Part 2 – Converting from RF2 to RF3
Part 3 – Node failure rebuild performance with RF3
Part 4 – Converting RF3 to Erasure Coding (EC-X)
Part 5 – Read I/O during CVM maintenance or failures
Part 6 – Write I/O during CVM maintenance or failures
Part 7 – Read & Write I/O during Hypervisor upgrades
Part 8 – Node failure rebuild performance with RF3 & Erasure Coding (EC-X)
Part 9 – Self healing
Part 10: Nutanix Resiliency – Part 10 – Disk Scrubbing / Checksums