As discussed in Part 1, we have proven HPE have made false claims about Nutanix snapshot capabilities as part of the #HPEDare2Compare twitter campaign.
In part 2, I explained how HPE/Simplivity’s 10:1 data reduction HyperGuarantee is nothing more than smoke and mirrors and that most vendors can provide the same if not greater efficiencies, even without hardware acceleration.
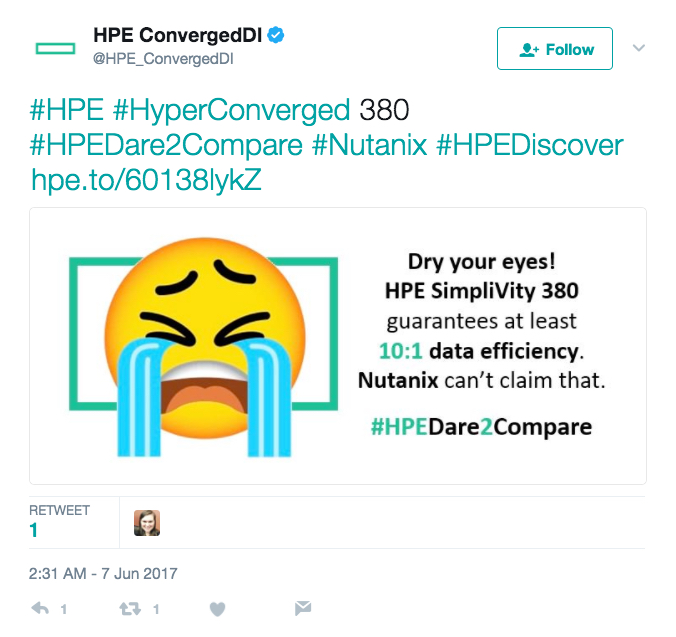
Now in part 3, I will respond to yet another false claim (below) that Nutanix cannot support dedupe without 8vCPUs.
#HPE #HyperConverged 380 #HPEDare2Compare #Nutanix #HPEDiscover https://t.co/TDmGFFi5G8 pic.twitter.com/Gd5idm16Mj
— HPE ConvergedDI (@HPE_ConvergedDI) June 7, 2017
This claim is interesting for a number of reasons.
1. There is no minimum or additional vCPU requirement for enabling deduplication.
The only additional CVM (Controller VM) requirement for enabling of deduplication is detailed in the Nutanix Portal (online documentation) which states:
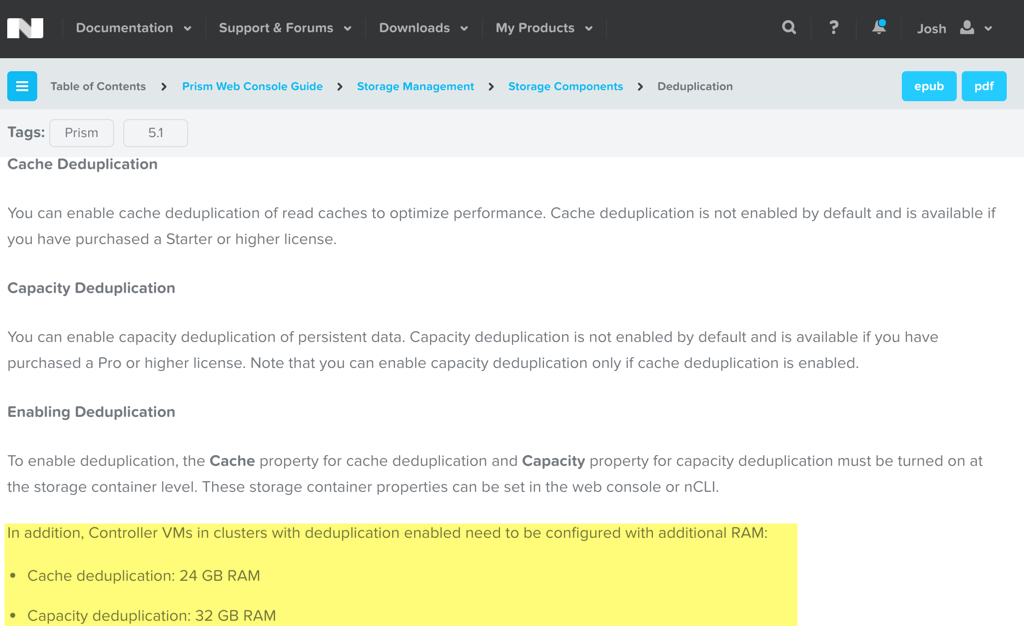
There is no additional vCPU requirement for enabling cache or capacity deduplication.
I note that the maximum 32GB RAM requirement is well below the RAM requirements for the HPE SVT product which can exceed 100GB RAM per node.
2. Deduplication is part of our IO engine (stargate) which is limited in AOS to N-2 vCPUs.
In short, this means the maximum number of vCPUs that stargate can use of a 8vCPU CVM is 6. However, this 6 vCPUs is not just for dedupe, its to process all I/O and things like statistics for PRISM (our HTML 5 GUI). Depending on the workload, only a fraction of the maximum 6 vCPUs are used, allowing those cores to be used for other workloads. (Hey, this is virtualization after all)
Deduplication itself uses a small fraction of the N-2 CPU cores and this brings us to my next point which speaks to the efficiency of the Nutanix deduplication compared to other vendors like HPE SVT who brute force dedupe all data regardless of the ratio which is clearly inefficient.
3. Nutanix Controller VM (CVM) CPU usage depends on the workload and feature set being used.
This is a critical point, Nutanix has configurable data reduction at a per vDisk granularity, Meaning for workloads which do not have a dataset which provides significant (or any) savings from deduplication, it can be left disabled (default).
This ensures CVM resources are not wasted performing what I refer to as “brute force” data reduction on all data regardless of the benefits.
4. Nutanix actually has global deduplication which spans across all nodes within a cluster whereas HPE Simplivity deduplication is not truly global. HPE Simplivity does not form a cluster of nodes, the nodes act more like HA pairs for the virtual machines and the deduplication in simple terms in with one or a pair of HPE SVT nodes.
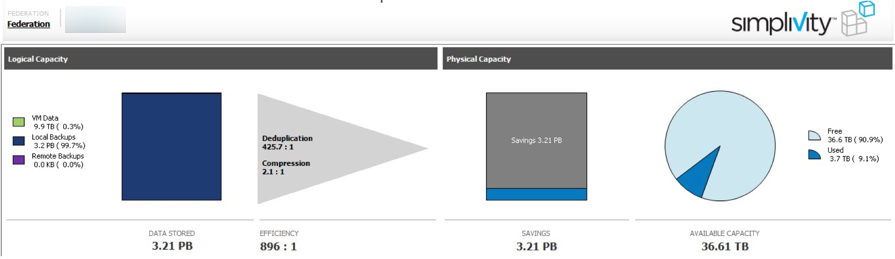
I’ve shown this where 4 copies of the same appliance are deployed across four HPE SVT nodes and the deduplication ratio is only 2.1:1, if the deduplication was global the rate would be closer to, if not 4:1 and this is what we see on Nutanix.
Define "globally": Deployed a VM four times on 4 x SVT nodes & it's only a 2.1:1 dedupe ratio. Looks like dedupe is across two nodes.#HCI pic.twitter.com/xi2LfaUSKF
— Josh Odgers (@josh_odgers) June 5, 2017
Nutanix can also have defined deduplication boundaries, so customers needing to seperate data for any reason (e.g.: Multi-tenancy / Compliance) can create two containers, both with deduplication enabled and enjoy global deduplication across the entire cluster without having customers refer to the same blocks.
5. Deduplication is vastly less valuable than vendors lead you to believe!
I can’t stress this point enough. Deduplication is a great technology and it works very well on many different platforms depending on the dataset.
But deduplication does not solve 99.9% of the challenges in the datacenter, and is one of the most overrated capabilities in storage.
Even if Nutanix did not support deduplication at all, it would not prevent all our existing and future customers achieving great business outcomes. If a vendor such as HPE SVT want to claim they have the best dedupe in the world, I don’t think anyone really cares, because even if it was true (which in my opinion it is not), then the value of Nutanix is so far beyond the basic storage functionality that we’re still far and away the market leader that deduplication it’s all but a moot point.
For more information about what the vCPUs assigned to the Nutanix CVM provide beyond storage functions, check out the following posts which addresses FUD from VMware about the CVMs overheads and the value the CVM provides much of which is unique to Nutanix.
Nutanix CVM/AHV & vSphere/VSAN overheads
Cost vs Reward for the Nutanix Controller VM (CVM)
Return to the Dare2Compare Index: