I am pleased to say Nutanix and our OEMs are now offering even more flexibility with our “Configure To Order” option (a.k.a CTO) by allowing any node type, yes ANY node type to be configured with all flash.
Why is this so cool, well Nutanix and our OEMs (Dell XC & Lenovo HX) have a wide range of models which customers can choose from and for customers who require large usable capacity of high performance storage, this is a simple way to get a pre-certified solution with all the flexibility of build your own without the risks.

With this increased level of flexibility, the argument for BYO/HCL is all but moot in my opinion.
So let’s think about what this means.
The NX-8150, a 1 node per 2RU product (which I was heavily involved in the design of) will now support 24 x SSDs!
Even with the currently supported SSDs (1.92TB each), this would mean >46TB of RAW SSD capacity along with dual Broadwell CPUs and up to 768GB RAM.
Note: Higher capacity SSDs are coming soon to provide even more capacity!
Now with 24 x SSDs that is some serious power!
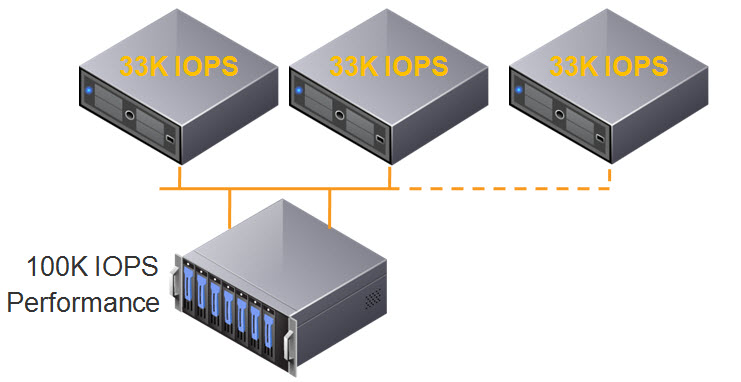
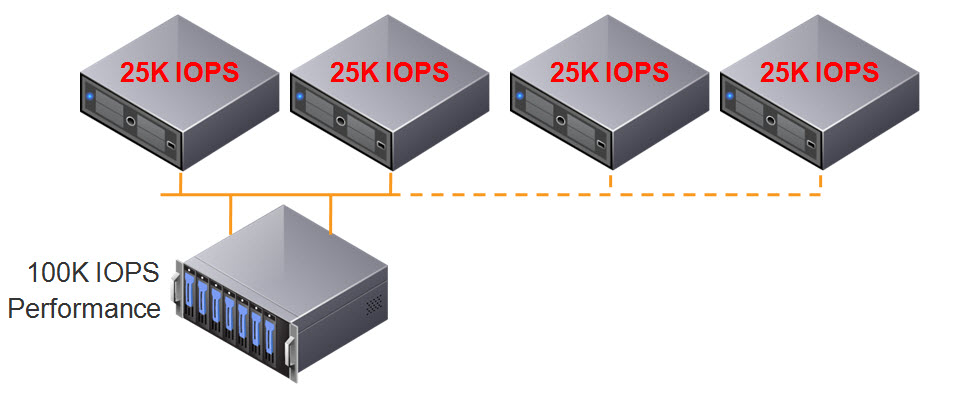
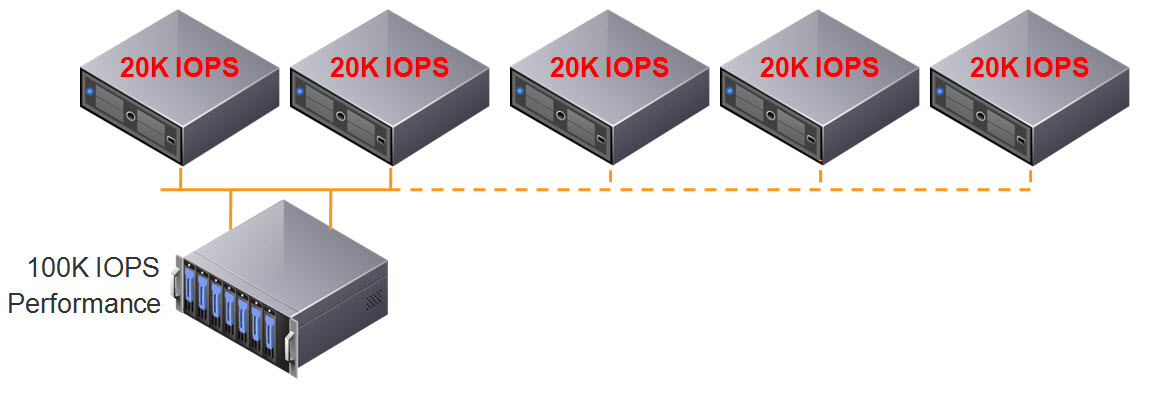
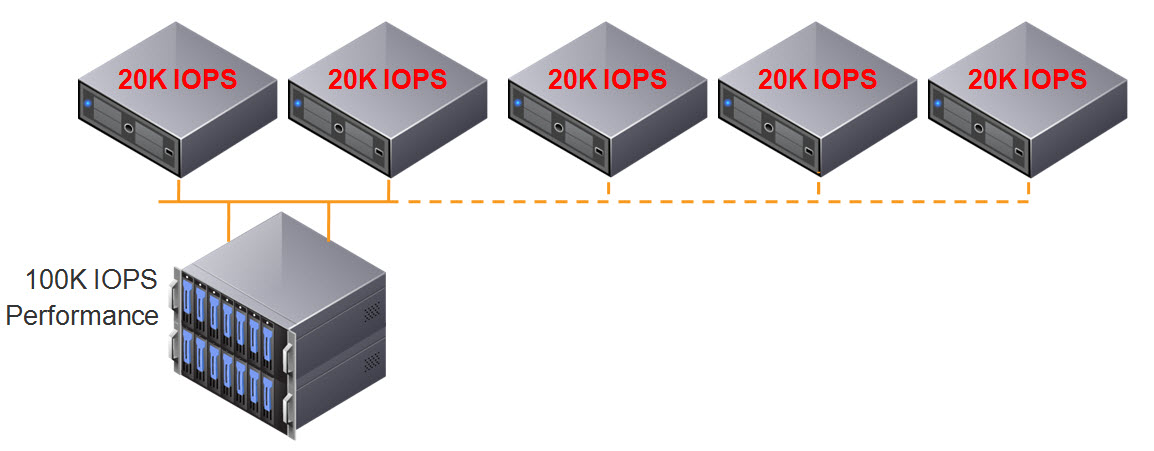
What’s also exciting is this doesn’t just mean higher flash capacity, it also means higher performance. This is because Nutanix persistent write buffer (OpLog) is striped across all SSDs in a node, this means the write performance can benefit from all SSDs in the node, in the case of that’s NX8150 that’s 24 drives!
Combine this with the fact Nutanix now supports any node as storage only, and this gives customers near unlimited flexibility without the risk/complexity of BYO/HCL options.
After all, the hardware is commodity, all the value is in the software so who cares what HW it runs on as long as its reliable.
Summary:
- Configure to Order (CTO) now allows any node type to be configured with All Flash
- All Flash nodes can also be Storage Only nodes
- Write Performance takes advantage of all SSDs in a node
- Nutanix Configure to Order (CTO) option makes the argument for BYO/HCL options all but moot.
Related .NEXT 2016 Posts
- What’s .NEXT 2016 – All Flash Everywhere!
- What’s .NEXT 2016 – Acropolis File Services
- What’s .NEXT 2016 – Acropolis X-Fit
- What’s .NEXT 2016 – Any node can be storage only
- What’s .NEXT 2016 – Metro Availability Witness
- What’s .NEXT 2016 – PRISM integrated Network configuration for AHV
- What’s .NEXT 2016 – Enhanced & Adaptive Compression
- What’s .NEXT 2016 – Acropolis Block Services
- What’s .NEXT 2016 – Self Service Restore