In this series I’ve covered a wide range of topics showing how resilient the Nutanix platform is including being able to maintain data integrity for new writes during failures and the ability to rebuild after a failure in a timely manner to minimise the risk of a subsequent failure causing problems.
Despite all of this information, competing vendors still try to discredit the data integrity that Nutanix provides with claims such as “rebuild performance doesn’t matter if both copies of data are lost” which is an overly simple way to look at things since the chance of both copies of data being lost are extremely low, and of course Nutanix supports RF3 for customers who wish to store three copies of data for maximum resiliency.
So let’s get into Part 10 where we cover two critical topics, Disk Scrubbing and Checksums both of which you will learn help ensure RF2 and RF3 deployments are extremely resilient and highly unlikely to experience scenarios where data could be lost.
Let’s start with Checksums, what are they?
A checksum is a small amount of data created during a write operation which can later be read back to verify if the actual data is intact (i.e.: not corrupted).
Disk scrubbing on the other hand is a background task which periodically checks the data for consistency and if any errors are detected, disk scrubbing initiates an error correction process to fix single correctable errors.
Nutanix performs checksums for every write operation (RF2 or RF3) and verifies the checksum for every read operation! This means that data integrity is part of the IO path and is not and cannot be skipped or turned off.
Data integrity is the number 1 priority for any storage platform which is why Nutanix does not and will never provide an option to turn checksum off.
Since Nutanix performs a checksum on read, it means that data being accessed is always being checked and if any form of corruption has occurred, Nutanix AOS automatically retrieves the data from the RF copy and services the IO and concurrently corrects the error/corruption to ensure subsequent failures do not cause data loss.
The speed at which Nutanix can rebuild from a node/drive or extent (1MB block of data) failure is critical to maintaining data integrity.
But what about cold data?
Many environments have huge amounts of cold data, meaning it’s not being accessed frequently, so the checksum on read operation wont be checking that data as frequently if at all if the data is not accessed so how do we protect that data?
Simple, Disk Scrubbing.
For data which has not been accessed via front end read operations (i.e.: Reads from a VM/app), the Nutanix implementation of disk scrubbing checks cold data once per day.
The disk scrubbing task is performed concurrently across all drives in the cluster so the chance of multiple concurrent failure occurring such as a drive failure and a corrupted extent (1MB block of data) and for those two drives to be storing the same data is extremely low and that’s assuming you’re using RF2 (two copies of data).
The failures would need to be timed so perfectly that no read operation had occurred on that extent in the last 24hrs AND background disk scrubbing had not been performed on both copies of data AND Nutanix AOS predictive drive failure had not detected a drive degrading and already proactively re-protected the data.
Now assuming that scenario arose, the drive failure would also have to be storing the exact same extent as the corrupted data block, which even in a small 4 node cluster such as a NX3460, you have 24 drives so the probability is extremely low. The larger the cluster the lower the chance of this already unlikely scenario and the faster the cluster can rebuild as we’ve learned earlier in the series.
If you still feel it’s too high a risk and feel strongly all those events will line up perfectly, then deploy RF3 and you would now have to have all the stars align in addition to three concurrent failures to experience data loss.
For those of you who have deployed VSAN, disk scrubbing is only performed once a year AND VMware frequently recommend turning checksums off, including in their SAP HANA documentation which has subsequently been updated after I called them out because this is putting customers at a high and unnecessary risk of data loss.
#DellEMC & #VMware want you to run #SAP HANA on #vSAN but they can only meet the performance requirements if they disable checksums, which in short puts you at high risk of data corruption.
Do not use vSAN – This is beyond a joke
Source: https://t.co/pvNjHMUZPu#CIO #sysadmin pic.twitter.com/IdFuHuzPbX
— Josh Odgers (@josh_odgers) September 18, 2018
Nutanix also has the ability to monitor the background disk scrubbing activity, the below screen shot shows the scan stats for Disk 126 which in this environment is a 2TB SATA drive at around 75% utilisation.
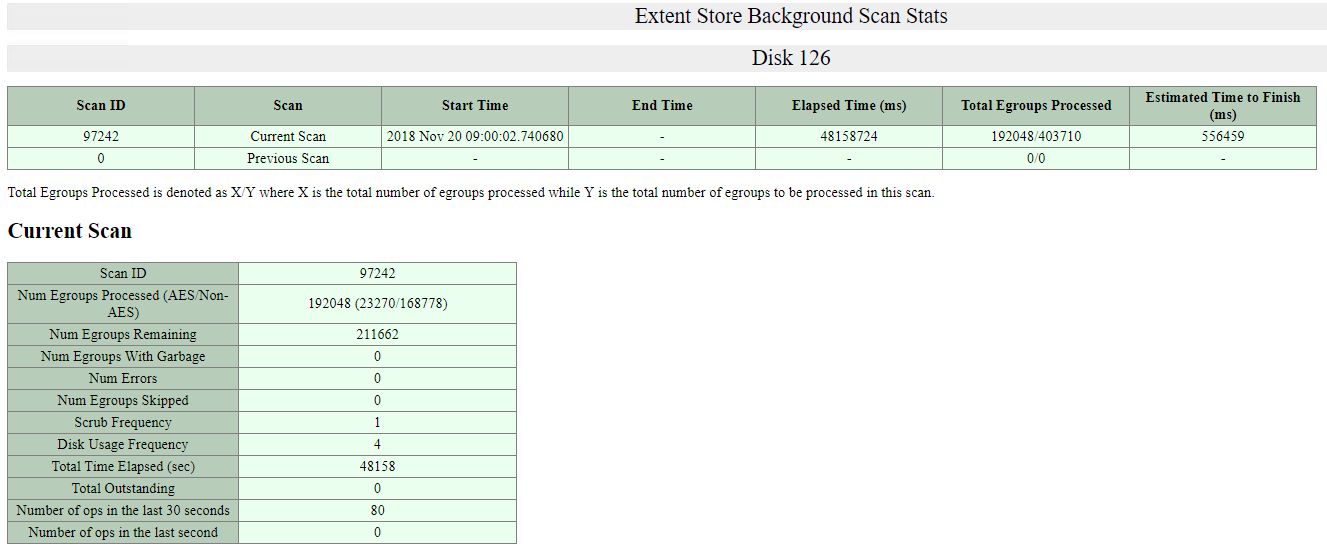

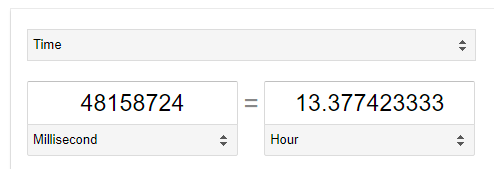
AOS ensures disk scrubbing occurs at a speed which guarantees the scrubbing of the entire disk regardless of size is finished every 24 hours, as per the above screenshot this scan has been running for 48158724ms or according to google, 13.3hrs with 556459ms (0.15hrs) ETA to complete.
If you combine the distributed nature of the Acropolis Distributed Storage Fabric (ADSF) where data is dynamically spread evenly based on capacity and performance, a clusters ability to tolerate multiple concurrent drives failures per node, checksums being performed on every read/write operation, disk scrubbing being completed every day, proactive monitoring of hard drive/SSD health to in many cases re-protect data before a drive fails as well at the sheer speed that ADSF can rebuild data following failures, it’s easy to see why even using Resiliency Factor 2 (RF2) provides excellent resiliency.
Still not satisfied, change the Resiliency Factor to 3 (RF3) and you have yet another layer of protection and you get even more protection for the workloads you choose to enable RF3 for.
When considering your Resiliency Factor, or Failures to Tolerate in vSAN language, do not make the mistake of thinking two copies of data on Nutanix and vSAN is equivalent, Nutanix RF2 is vastly more resilient than FTT1 (2 copies) on vSAN which is why VMware frequently recommend FTT2 (3 copies of data). This actually makes sense because of the following reasons:
- vSAN is not a distributed storage fabric
- vSAN rebuild performance is slow and high impact
- vSAN disk scrubbing is only performed once a year
- VMware frequently recommend to turn checksums OFF (!!!)
- A single cache drive failure takes an entire disk group offline
- With all flash vSAN using compression and/or dedupe, a single drive brings down the entire disk group
Architecture matters, and for anyone who takes the time to investigate beyond the marketing slides of HCI and storage products will see that Nutanix ADSF is the clear leader especially when it comes to scalability, resiliency & data integrity.
Other companies/products are clear leaders in Marketecture (to be blunt, Bullshit like in-kernel being an advantage and 10:1 dedupe) but Nutanix leads where it matters with a solid architecture which delivers real business outcomes.
Index:
Part 1 – Node failure rebuild performance
Part 2 – Converting from RF2 to RF3
Part 3 – Node failure rebuild performance with RF3
Part 4 – Converting RF3 to Erasure Coding (EC-X)
Part 5 – Read I/O during CVM maintenance or failures
Part 6 – Write I/O during CVM maintenance or failures
Part 7 – Read & Write I/O during Hypervisor upgrades
Part 8 – Node failure rebuild performance with RF3 & Erasure Coding (EC-X)
Part 9 – Self healing
Part 10: Nutanix Resiliency – Part 10 – Disk Scrubbing / Checksums