Virtualization of business critical application has been common place for a number of years, however it is less well known that these business critical applications are also regularly deployed on Nutanix Hyper-converged Infrastructure (HCI) as I discuss in the following post:
Think HCI is not an ideal way to run your mission-critical x86 workloads? Think again!
I am regularly involved in discussions with customers about how well MS Exchange and other business critical applications perform on Nutanix especially during:
- Storage software upgrades (Acropolis Base Software)
- Hypervisor upgrade
- VMs Migrations (e.g.: vMotion)
- Failure scenarios.
Customers also ask how Data Locality works with workloads like Exchange which have large amounts of data, what overheads are there if any, how much data is served local vs remote and so on.
As a result, I have created the following series of Videos demonstrating the following:
- Setting a baseline for Jetstress performance on Node 1
- Migrating VM to a 2nd node and repeating the Jetstress performance test
- Migrating VM to a 3rd node and repeating the Jetstress performance test
- Migrating VM to a 4th node and repeating the Jetstress performance test
- Migrating the VM back to the 1st node and repeating the Jetstress performance test
- Repeating the test on the 2nd, 3rd and 4th nodes (second Jetstress run for comparison)
- Performing a Jetstress performance test on a VM with the local Nutanix Controller VM (CVM) offline (to simulate a CVM failure, Storage Maintenance or Upgrade scenarios)
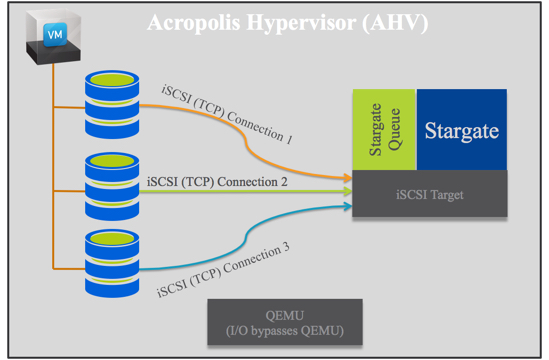
During the above videos I will show advanced Nutanix Distributed Storage Fabric (NDSF) performance statistics such as how Write I/O is being served and What percentage of data is being served locally verses remotely.
Enjoy the videos:
Part 1 – Setting a baseline for Jetstress performance on Nutanix AHV
Part 2 – Migrating Jetstress to 2nd node and repeating Jetstress test
Part 3 – Migrating Jetstress to 3rd node and repeating Jetstress test
Part 4 – Migrating Jetstress to 4th node and repeating Jetstress test
Part 5 through 8 – Repeat Jetstress Tests on all four nodes. (Coming soon)
Part 9 – Take the local Nutanix Controller VM (CVM) offline and repeat test (Coming soon)
Part 10 – Scale out Performance Validation (Coming soon)
Related Articles:
- MS Exchange on Nutanix Acropolis Hypervisor (AHV)
- MS Exchange on Nutanix now a MS validated ESRP solution
- Peak performance vs Real World – Exchange on Nutanix Acropolis Hypervisor (AHV)
- How to successfully Virtualize MS Exchange
- Deduplication and MS Exchange
- Think HCI is not ideal way to run your mission-critical x86 workloads? Think again!
- Why Nutanix Acropolis hypervisor (AHV) is the next generation hypervisor