Lets start with describing an common performance issue with Horizon View (Formally VMware View) environments using Linked Clones.
3. Performance is 100% dependant on the Storage Area Network or Storage Controllers for performance and where latency or contention exists, performance will suffer.
2. Read I/O heavy tasks such as AV scans are a high impact to the ESXi host, Storage Network and Storage Controllers which can have a high impact on other workloads using the same shared storage (virtual and/or physical)
One thing VMware has done to improve this situation is create Content Based Read Cache (CBRC a.k.a View Storage Accelerator).
CBRC has been shown in many tests to greatly improve the performance especially during boot storms, login storms and antivirus scans.
Andre Leibovici (@andreleibovici) wrote a great article on his blog “myvirtualcloud.net” showing the benefits on CBRC here which in summary showed that the I/O to the underlying storage was reduced and performance improved in all three of the above mentioned scenarios.
While CBRC does improve the situation, it does have some limitations.
1. Restricted to 2048MB (2GB)
2. The Bulk of the user data (Read I/O) and ALL Write I/O is still serviced remotely on the Storage Array over the Storage Area Network which still places a serious dependency on the Storage Network and (limited number of) Storage Controllers.
3. Virtual machine host caching is applied only when the virtual machine is powered off. Configuring host caching for a powered-on virtual machine requires virtual machine shutdown to apply the configuration. In the case of linked clone virtual machines, caching cannot be enabled when any of the virtual machines based on the same shared base disk are powered on.
4. Enabling host caching will create additional disks for each boot VMDK and snapshot VMDK, which results in increased storage utilization.
5. If the administrator changes the advanced configuration parameters, some changes might require the vSphere CBRC module to be unloaded and reloaded for the changes to take effect.
6. Host caching cannot be configured for non-vCenter managed pools, or terminal server pools.
Note: The Source for some of the above limitations is the VMware View Storage Accelerator – View 5.1 White paper which can be found here.
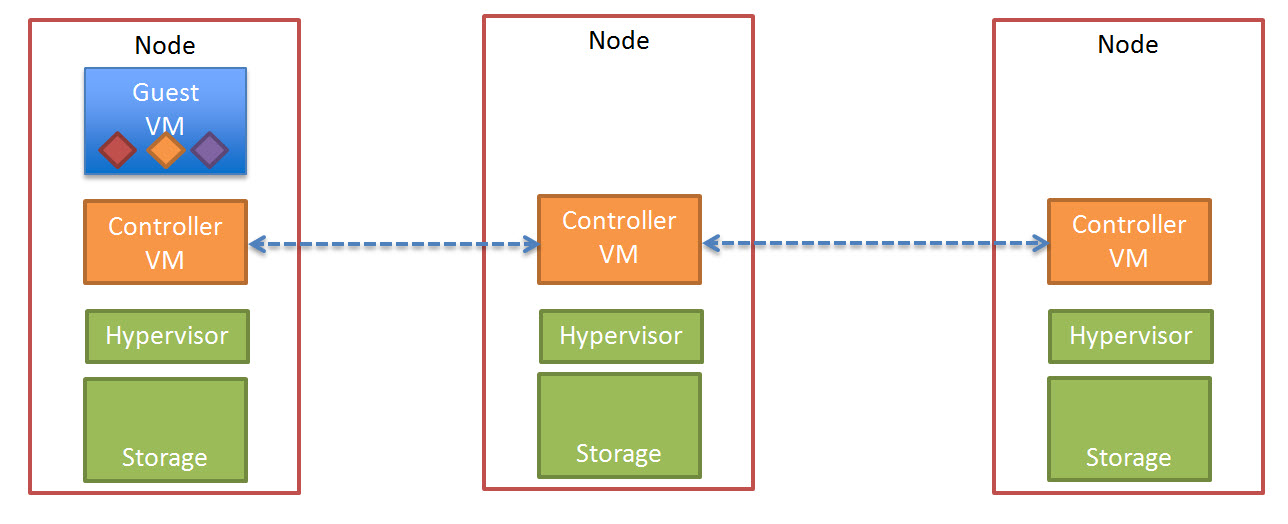
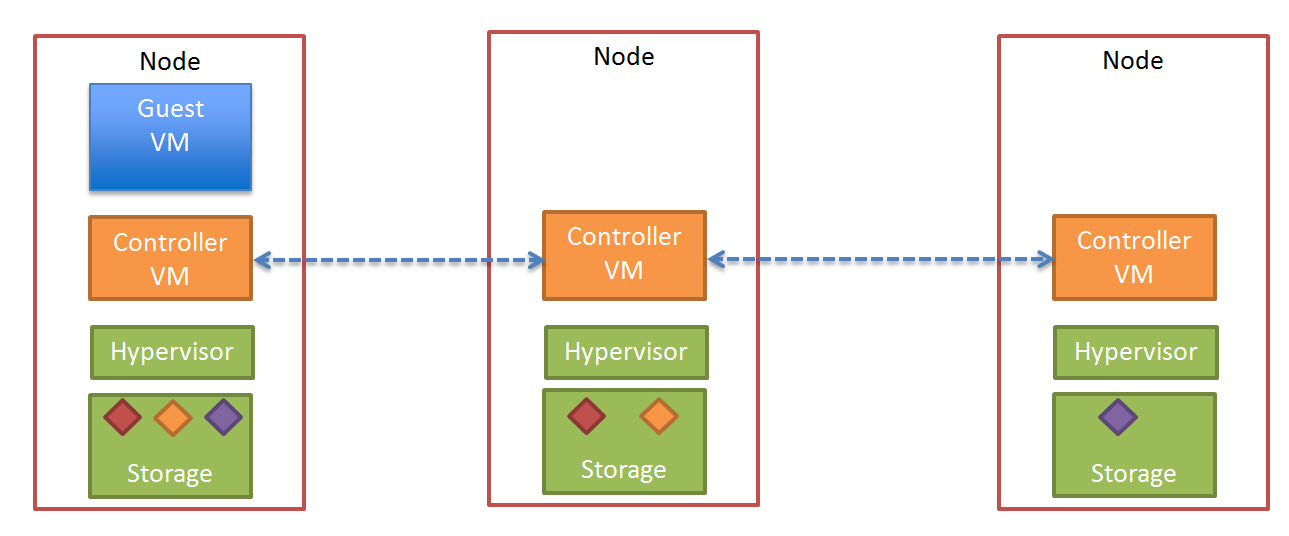
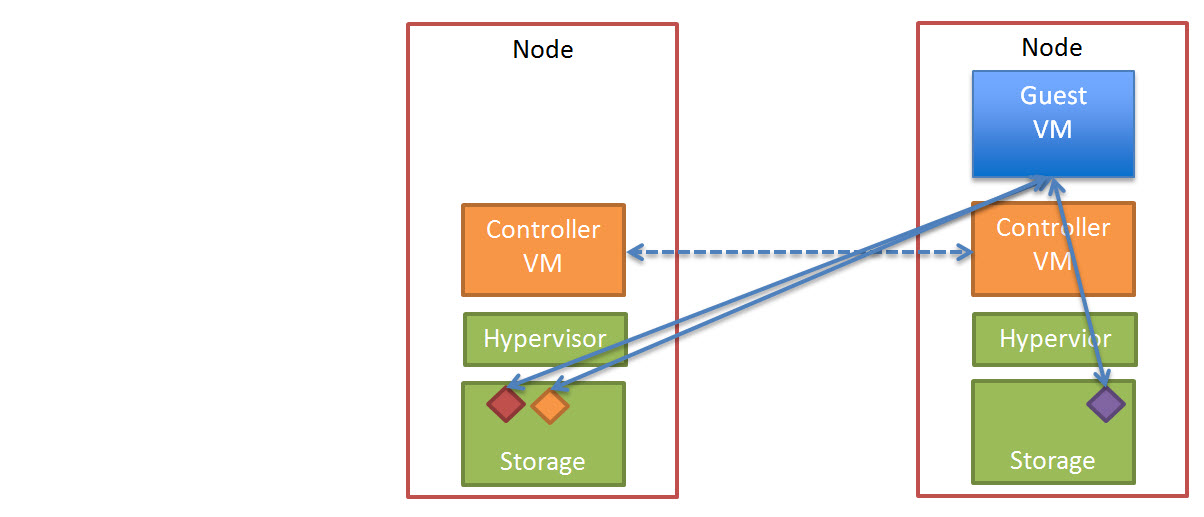
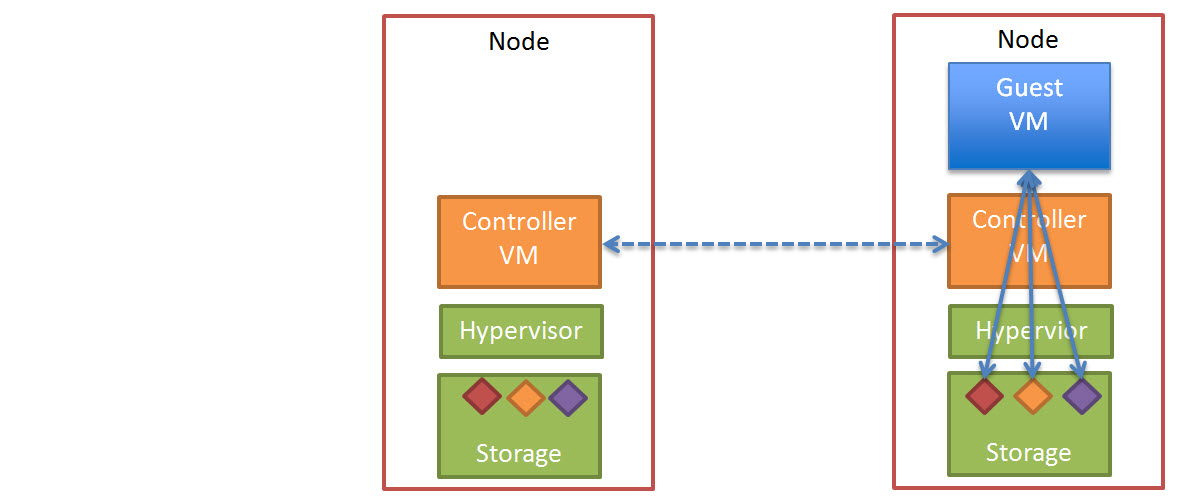
In a Nutanix environment, there is a number of features which go further to address these issue. The first is called “Extent Cache” which is a READ cache in DRAM of each Controller VM (CVM). The “Extent Cache” is by default 3072MB but can be increased to whatever size suits your environment.
The below is a visual representation of the Nutanix Extent Cache.

Some of the benefits of Nutanix Extent Cache are
1. Can be sized to suit your requirements (Not limited to 2GB)
2. Does not require the use of CBRC
3. Reduced overhead on the Storage Network (IP Network) as more read I/O can be cached locally
4. Due to Nutanix DFS “Data locality”, data that not stored in Extent Cache is generally accessed locally via SSD. This further reduces the overhead on the Storage Network & dramatically reduces the impact on other controllers within the Nutanix cluster- See my post Data Locality & Why is important for vSphere DRS clusters for more information about Data locality
5. During boot storms, login storms and antivirus scans more data can be served from Cache (Extent Cache) and less read I/O is forced to be served by SSD (or local SATA drives if the data is “Cold”). This not only improves Read performance but makes more I/O available for Write operations which are generally >=65% in VDI environments
6. Works with any Virtual Machine, not just VDI and is hypervisor agnostic.
7. No need to configure a View Desktop Pool to use “Host Caching” as the “Extent Cache” performs this function (and more) at the Nutanix layer automatically
8. No need to configure “Regenerate Cache” or “Blackout Times” which is required for CBRC
9. No additional storage is used by Nutanix Extent Cache
10. Changes to the Nutanix Extent Cache can be done without disruption to the Virtual machines
Note: Extent cache is not limited to desktop workloads, it also works with any type of virtual machine and is operating system agnostic.
In Part 2, We discuss the Nutanix Dynamic Shadow’s feature will be discussed to show how Nutanix ensures data locality for 100% read only data such as Linked Clone Replica’s.
A special Thank you to Jason Langone VCDX#54 (@langonej) for reviewing this post and to Tabrez Memon one of the brilliant Engineers at Nutanix who has worked on features discussed in this post and provided valuable input into this series.